
Искусственный интеллект вновь вышел в число наиболее обсуждаемых мировых проблем


Июль 2023 года в США, Китае и России стал месяцем активного обсуждения проблем дальнейшего развития искусственного интеллекта.
Каковы шансы апокалипсиса с помощью ИИ?
10 июля 2023 года группа исследователей США, в которую вошли Эзра Каргер, экономист из Федерального резервного банка Чикаго, и Филип Тетлок, политолог из Пенсильванского университета, опубликовали в The Economist рабочий документ, в котором пытались пролить свет на этот вопрос путем систематического изучения мнений двух разного рода специалистов. С одной стороны, это предмет или «область», специалисты по ядерной войне, биологическому оружию, ИИ и вымиранию человечества. С другой находилась группа «суперпрогнозистов» — предсказателей общего назначения, которые делали точные прогнозы на самые разные темы, от результатов выборов до начала войн.
Исследователи наняли 89 суперпрогнозистов, 65 экспертов в предметной области и 15 экспертов по «риску исчезновения» в целом. Собравшимся было предложено рассмотреть два различных вида бедствий. «Катастрофа» определялась как событие, в результате которого погибло всего 10% людей в мире, или около 800 миллионов человек. (Для сравнения, Вторая мировая война, по оценкам, унесла жизни около 3% двухмиллиардного населения мира в то время.) «Вымирание» определялось как событие, которое уничтожило всех, за исключением, возможно, большинство, 5000 удачливых (или невезучих) душ.
Обеим группам было предложено оценить вероятность всего, начиная от неизбежных событий, таких как вымирание, вызванное ИИ, или ядерной войны, и заканчивая более мелкими вопросами, например , могут ли произойти тревожные достижения в возможностях ИИ, которые могли бы послужить указателями на будущую дорогу к грядущей катастрофе.
Самый поразительный вывод исследования заключался в том, что эксперты в предметной области, которые, как правило, доминируют в публичных разговорах об экзистенциальных рисках, кажутся более мрачными в отношении будущего, чем суперпрогнозисты. Эксперты подсчитали, что к 2100 году вероятность катастрофы составляет около 20%, а вероятность исчезновения — 6%. Суперпрогнозисты дали этим событиям вероятности в 9% и 1% каждое.
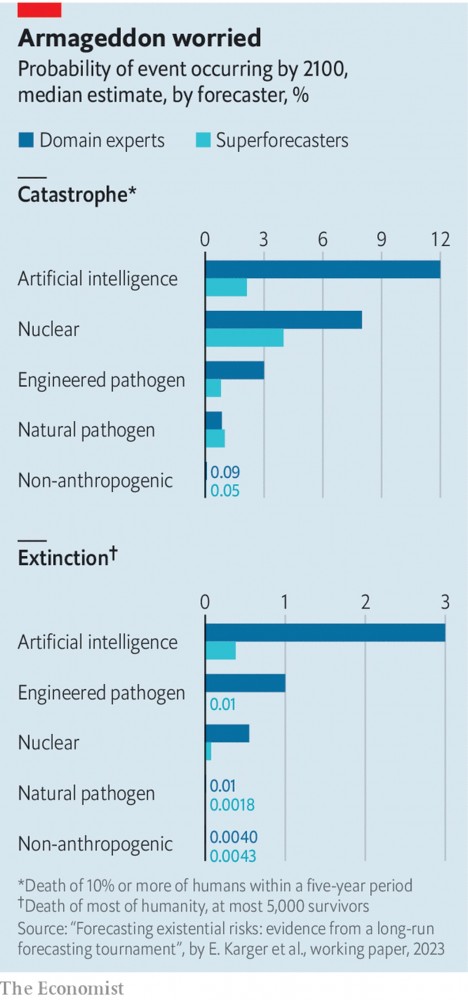
Этот широкий разрыв скрывал некоторые интересные детали. Разница между двумя группами была наибольшей при рассмотрении рисков, связанных с ИИ.
Средний суперпрогнозист подсчитал, что вероятность катастрофы, вызванной ИИ, составляет 2,1% , а вероятность вымирания, вызванного ИИ, к концу века составляет 0,38%.
Эксперты по искусственному интеллекту , напротив, присвоили этим двум событиям вероятность 12% и 3% соответственно. Когда дело дошло до пандемий, суперпрогнозисты были более пессимистичны, чем эксперты в предметной области, в отношении рисков, связанных с естественным заболеванием.
Возможно, самым интересным результатом было то, что, хотя группы разошлись во мнениях относительно точного размера риска, обе группы назвали ИИ самым большим беспокойством, независимо от того, думали ли они о катастрофе или вымирании (см. Диаграмму).
По словам Дэна Мейланда, суперпрогнозиста, участвовавшего в исследовании, одной из причин сильных результатов ИИ является то, что он действует как «множитель силы» в отношении других рисков, таких как ядерное оружие. Как и в случае с ядерной войной или ударом астероида, ИИ (скажем, в виде вооруженных роботов) может напрямую убивать людей. Но он также «мог служить для заточки топора другого палача», так сказать. Если бы люди использовали ИИ, например, для разработки более мощного биологического оружия, это внесло бы существенный вклад, хотя и косвенно, в любую последующую катастрофу.
Но хотя суперпрогнозисты относились к ИИ пессимистично, они также относились к нему относительно неуверенно. Мир жил с ядерным оружием почти 80 лет. Тот факт, что ядерной войны еще не было, представляет собой ценные данные, которые можно использовать для прогнозирования того, может ли она произойти в будущем.
ИИ в нынешнем значении этого термина, намного новее. Появление современных мощных моделей машинного обучения относится к началу 2010-х годов. И область все еще быстро развивается. Это оставляет гораздо меньше исторических данных, на которых можно основывать прогнозы.
Суперпрогнозисты и эксперты по ИИ придерживались совершенно разных взглядов на то, как общества могут отреагировать на небольшой ущерб, причиненный ИИ. Суперпрогнозисты склонны думать, что такой ущерб вызовет тщательное изучение и регулирование, чтобы предотвратить более серьезные проблемы позже. Эксперты в предметной области, напротив, склонны думать, что коммерческие и геополитические стимулы могут перевесить опасения по поводу безопасности, даже после того, как был нанесен реальный ущерб.
ИИ в США
Байден погрузился в искусственный интеллект
21 июля 2023 года Президент США Байден встретился с семью ведущими компаниями, занимающихся искусственным интеллектом (Amazon, Google и Meta* и др.), которые взяли на себя добровольные обязательства по управлению рисками, связанными с новой технологией.
Эти семь компаний согласились на добровольные обязательства по ответственным инновациям. Эти обязательства, которые компании будут выполнять немедленно, подчеркивают три фундаментальных принципа: безопасность, безопасность и доверие.
Во-первых, компании обязаны убедиться, что их технология безопасна, прежде чем выпустить ее для широкой публики. Это означает тестирование возможностей их систем, оценку их потенциального риска и обнародование результатов этих оценок.
Во-вторых, компании должны уделять первоочередное внимание безопасности своих систем, защищая свои модели от киберугроз и управляя рисками для национальной безопасности США, а также обмениваясь передовым опытом и необходимыми отраслевыми стандартами.
В-третьих, компании обязаны завоевать доверие людей и предоставить пользователям возможность принимать обоснованные решения.
Маркировка контента, который был изменен или создан искусственным интеллектом. Искоренение предрассудков и дискриминации, усиление защиты конфиденциальности и защита детей от вреда.
Добровольные гарантии — это лишь ранний предварительный шаг, поскольку Вашингтон и правительства всего мира спешат создать правовые и нормативные рамки для развития искусственного интеллекта. Соглашения включают в себя тестирование продуктов на наличие угроз безопасности и использование водяных знаков, чтобы потребители могли распознавать материалы, созданные искусственным интеллектом.
Объявление, сделанное 21 июля, отражает стремление администрации Байдена и законодателей срочно отреагировать на быстро развивающиеся технологии, даже несмотря на то, что законодатели изо всех сил пытаются регулировать социальные сети и другие технологии.
«В ближайшие недели я продолжу предпринимать исполнительные действия, чтобы помочь Америке проложить путь к ответственным инновациям», — сказал Байден. «И мы собираемся работать с обеими сторонами над разработкой соответствующего законодательства и правил».
Белый дом не сообщил подробностей о предстоящем указе президента, который будет касаться более серьезной проблемы: как контролировать способность Китая и других конкурентов завладеть новыми программами искусственного интеллекта или компонентами, используемыми для их разработки.
Это включает в себя новые ограничения на продвинутые полупроводники и ограничения на экспорт больших языковых моделей. Их трудно контролировать — большая часть программного обеспечения может поместиться в сжатом виде на флэш-накопителе.
Распоряжение может вызвать большее сопротивление со стороны отрасли, чем добровольные обязательства, озвученные 21 июля. Они, по словам экспертов, уже нашли отражение в практике вовлеченных компаний. Обещания не будут ограничивать планы компаний, занимающихся искусственным интеллектом, и не мешать развитию их технологий. И как добровольные обязательства, они не будут обеспечиваться государственными регулирующими органами.
«Мы рады взять на себя эти добровольные обязательства вместе с другими в этом секторе», — заявил Ник Клегг, президент по глобальным связям в Meta, материнской компании Facebook*. «Они являются важным первым шагом в обеспечении ответственных ограничений для ИИ и создают модель, которой должны следовать другие правительства».
В рамках гарантий компании согласились:
тестировать безопасность своих продуктов ИИ, частично независимыми экспертами;
осуществлять обмен информацией о своих продуктах с правительствами и другими сторонами, которые пытаются управлять рисками, связанными с технологией;
обеспечить, чтобы потребители могли обнаруживать материалы, созданные ИИ, путем внедрения водяных знаков или других средств идентификации сгенерированного контента;
публично сообщать о возможностях и ограничениях своих систем на регулярной основе, включая риски безопасности и доказательства предвзятости;
развернуть передовые инструменты искусственного интеллекта для решения самых больших проблем общества, таких как лечение рака и борьба с изменением климата;
проводить исследования рисков предвзятости, дискриминации и вторжения в частную жизнь из-за распространения инструментов ИИ.
В заявлении, объявляющем о соглашениях, администрация Байдена заявила, что компании должны гарантировать, что «инновации не будут осуществляться за счет прав и безопасности американцев».
«Компании, которые разрабатывают эти новые технологии, несут ответственность за обеспечение безопасности своей продукции», — говорится в заявлении администрации.
Для компаний стандарты, описанные 21 июля, служат двум целям:
попытка предотвратить или сформулировать законодательные и нормативные шаги с помощью самоконтроля;
как сигнал о том, что они обдумывают эту новую технологию вдумчиво и активно.
Но правила, которые они согласовали, в значительной степени являются наименьшим общим знаменателем и могут интерпретироваться каждой компанией по-разному. Например, фирмы привержены строгой кибербезопасности данных и кода, используемых для создания «языковых моделей», на основе которых разрабатываются генеративные программы ИИ. Но нет никакой конкретики в отношении того, что это означает — и компании в любом случае будут заинтересованы в защите своей интеллектуальной собственности.
И даже самые осторожные компании уязвимы. Microsoft, одна из фирм, присутствовавших на мероприятии в Белом доме вместе с Байденом, накануне встречи в Белом доме изо всех сил пыталась противостоять организованному китайским правительством взлому личных электронных писем американских чиновников, имевших дело с Китаем. Теперь выясняется, что Китай каким-то образом получил «закрытый ключ», принадлежащий Microsoft, который является ключом к аутентификации электронной почты — одной из наиболее тщательно охраняемых частей кода компании.
В результате соглашение вряд ли замедлит усилия по принятию законодательства и регулированию новых технологий.
Пол Барретт, заместитель директора Центра бизнеса и прав человека Стерна в Нью-Йоркском университете, сказал, что необходимо сделать больше для защиты от опасностей, которые искусственный интеллект представляет для общества.
«Жизненно важно, чтобы Конгресс вместе с Белым домом оперативно разработал законодательство, требующее прозрачности, защиты конфиденциальности, и активизировал исследования широкого спектра рисков, связанных с генеративным ИИ», — говорится в заявлении Барретта.
Европейские регулирующие органы готовы принять законы об искусственном интеллекте, что побудило многие компании поощрять законодательство США. Несколько законодателей в Конгрессе США представили законопроекты, которые включают лицензирование компаний ИИ для выпуска своих технологий, создание федерального агентства для надзора за отраслью и требования к конфиденциальности данных. Но члены Конгресса далеки от согласия в отношении правил и спешат изучить технологию.
Законодатели пытаются решить, как справиться с распространением технологий искусственного интеллекта, причем некоторые из них сосредоточены на рисках для потребителей, в то время как другие остро обеспокоены отставанием от противников, особенно от Китая, в гонке за доминирование в этой области.
Специальный комитет Палаты представителей по стратегической конкуренции с Китаем в июле 2023 года разослал двухпартийные письма американским венчурным компаниям с требованием рассчитаться за инвестиции, которые они вложили в китайские компании, занимающиеся искусственным интеллектом и полупроводниками. Эти письма приходят после нескольких месяцев, в течение которых различные комиссии Палаты представителей и Сената опрашивали самых влиятельных предпринимателей и критиков индустрии ИИ, чтобы определить, какие законодательные ограничения и стимулы следует изучить Конгрессу.
Многие из этих свидетелей, в том числе Сэм Альтман из стартапа OpenAI в Сан-Франциско, умоляли законодателей регулировать индустрию ИИ, указывая на то, что новая технология может нанести неправомерный вред. Но это регулирование медленно внедряется в Конгрессе, где многие законодатели все еще пытаются понять, что именно представляет собой технология ИИ.
В попытке улучшить понимание законодателей сенатор Чак Шумер, демократ от Нью-Йорка и лидер большинства, начал летом 2023 года серию слушаний для законодателей, чтобы услышать от государственных чиновников и экспертов о достоинствах и опасностях искусственного интеллекта в ряде областей.
Шумер также подготовил поправку к сенатской версии законопроекта о разрешении на оборону в 2023 году, чтобы:
стимулировать сотрудников Пентагона сообщать о потенциальных проблемах с инструментами ИИ;
заказать отчет Пентагона о том, как улучшить обмен данными ИИ;
улучшить отчётность об ИИ в индустрии финансовых услуг.
Расследование и регулирование
13 июля 2023 г. Федеральная торговая комиссия США (FTC)начала расследование в отношении OpenAI, стартапа искусственного интеллекта, создающего ChatGPT, на предмет того, наносил ли чат-бот вред потребителям путем сбора данных и публикации ложной информации о физических лицах.
В 20-страничном письме агентство сообщило, что также изучает методы обеспечения безопасности OpenAI. В своем письме FTC задала OpenAI десятки вопросов, в том числе о том, как стартап обучает свои модели ИИ и обрабатывает персональные данные, и заявила, что компания должна предоставить агентству документы и подробности.
FTC изучает вопрос о том, «причастна ли OpenAI к недобросовестным или вводящим в заблуждение методам обеспечения конфиденциальности или безопасности данных или к недобросовестным или вводящим в заблуждение методам, связанным с рисками причинения вреда потребителям», говорится в письме.
Расследование FTC представляет собой первую серьезную регулятивную угрозу США для OpenAI, одной из самых известных компаний в области искусственного интеллекта, и сигнализирует о том, что технология может подвергаться все более тщательному изучению, поскольку люди, предприятия и правительства используют больше продуктов на основе искусственного интеллекта. Быстро развивающаяся технология вызвала тревогу, поскольку чат-боты могут генерировать ответы в ответ на запросы, потенциально могут заменить людей на их работе и распространять дезинформацию.
Сэм Альтман, руководитель OpenAI, считает, что быстрорастущую индустрию искусственного интеллекта необходимо регулировать. В мае 2023 ujlf он свидетельствовал в Конгрессе, призывая принять закон об искусственном интеллекте, и посетил сотни законодателей, стремясь определить политическую повестку дня для этой технологии.
OpenAI уже подвергся давлению регулирующих органов на международном уровне. В марте 2023 года орган по защите данных Италии запретил ChatGPT, заявив, что OpenAI незаконно собирает личные данные пользователей и не имеет системы проверки возраста, чтобы предотвратить доступ несовершеннолетних к незаконным материалам. OpenAI восстановила доступ к системе в апреле 2023 года, заявив, что внесла изменения, о которых просили итальянские власти.
FTC действует в отношении ИИ с заметной скоростью, начав расследование менее чем через год после того, как OpenAI представила ChatGPT. Лина Хан, председатель FTC, заявила, что технологические компании должны регулироваться, пока технологии только зарождаются, а не только тогда, когда они становятся зрелыми.
В прошлом агентство обычно начинало расследования после серьезных публичных ошибок со стороны компании, таких как открытие расследования политики конфиденциальности Meta после сообщений о том, что оно передало пользовательские данные политической консалтинговой фирме Cambridge Analytica в 2018 году.
Г-жа Хан ранее заявляла, что индустрия ИИ нуждается в тщательном анализе.
«Хотя эти инструменты являются новыми, они не освобождаются от существующих правил, и Федеральная торговая комиссия будет энергично обеспечивать соблюдение законов, которые нам поручено администрировать, даже на этом новом рынке», — написала она в гостевом эссе в The New York Times в мае 2023 года. «Несмотря на то, что технология развивается быстро, мы уже видим несколько рисков».

13 июля 2023 года на слушаниях в Судебном комитете Палаты представителей г-жа Хан заявила: «ChatGPT и некоторые другие сервисы получают огромное количество данных. Нет никаких проверок того, какой тип данных вводится в эти компании». Она добавила, что поступали сообщения о появлении «конфиденциальной информации» людей.
Расследование может заставить OpenAI раскрыть свои методы создания ChatGPT и источники данных, которые он использует для создания своих систем искусственного интеллекта. Хотя OpenAI долгое время довольно открыто сообщала такую информацию, в последнее время она мало говорила о том, откуда берутся данные для ее систем ИИ и сколько используется для создания ChatGPT, вероятно, потому, что она настороженно относится к копированию конкурентами и опасается судебных исков. над использованием определенных наборов данных.
Чат-боты, которые также внедряются такими компаниями, как Google и Microsoft, представляют собой серьезный сдвиг в способах создания и использования компьютерного программного обеспечения. Они готовы заново изобрести поисковые системы в Интернете, такие как Google Search и Bing, говорящих цифровых помощников, таких как Alexa и Siri, и почтовые службы, такие как Gmail и Outlook.
Когда OpenAI выпустила ChatGPT в ноябре 2022 года, она мгновенно захватила воображение публики своей способностью отвечать на вопросы, писать стихи и рифмовать практически на любую тему. Но технология также может смешивать факты с вымыслом и даже создавать информацию — явление, которое учёные называют «галлюцинациями».
ChatGPT управляется тем, что исследователи ИИ называют нейронной сетью. Это та же технология, которая осуществляет перевод между французским и английским языками в таких сервисах, как Google Translate, и идентифицирует пешеходов, когда беспилотные автомобили перемещаются по городским улицам. Нейронная сеть обучается навыкам, анализируя данные. Например, определяя закономерности на тысячах фотографий кошек, он может научиться распознавать кошку.
Исследователи из таких лабораторий, как OpenAI, разработали нейронные сети, которые анализируют огромное количество цифрового текста, включая статьи в Википедии, книги, новости и журналы онлайн-чатов. Эти системы, известные как большие языковые модели, научились генерировать текст самостоятельно, но могут повторять ошибочную информацию или комбинировать факты таким образом, что получается неточная информация.
В марте 2023 года Центр искусственного интеллекта и цифровой политики, правозащитная группа, выступающая за этичное использование технологий, обратилась к FTC с просьбой заблокировать OpenAI от выпуска новых коммерческих версий ChatGPT, сославшись на опасения, связанные с предвзятостью, дезинформацией и безопасностью.
Организация обновила жалобу в июле, описав дополнительные способы, которыми чат-бот может причинить вред, на что, по ее словам, также указал OpenAI.
«Сама компания признала риски, связанные с выпуском продукта, и призвала к регулированию», — сказал Марк Ротенберг, президент и основатель Центра искусственного интеллекта и цифровой политики. «Федеральная торговая комиссия должна действовать».
OpenAI работает над улучшением ChatGPT и сокращением количества предвзятых, ложных или иных вредных материалов. Когда сотрудники и другие тестировщики используют систему, компания просит их оценить полезность и правдивость ее ответов. Затем с помощью метода, называемого обучением с подкреплением, он использует эти рейтинги, чтобы более точно определить, что чат-бот будет делать, а что нет.
Расследование FTC в отношении OpenAI может занять много месяцев, и неясно, приведет ли оно к каким-либо действиям со стороны агентства. Такие расследования являются частными и часто включают показания высших руководителей корпораций.
Устранение потенциальных рисков, связанных с искусственным интеллектом
Картер С. Прайс (содиректор Центра масштабируемых вычислений и анализа RAND) и Мишель Вудс (заместитель директора отдела исследований национальной безопасности RAND) написали 13 июля 2023 года в комментариях на сайте корпорации, что хотя были предприняты попытки перечислить риски ИИ, простая категоризация могла бы разделить их на текущие риски, которые будут усугубляться ИИ, такие как террористы, использующие ИИ для разработки более смертоносного биологического оружия, и новые риски, специфичные для ИИ, такие как ИИ, выбирающий уничтожение человечества в качестве оптимальное решение проблемы изменения климата.
Подходы к управлению рисками, используемые для борьбы с текущими угрозами, скорее всего, потребуется пересмотреть, чтобы учесть непредвиденные возможности, которые может предоставить ИИ. Хотя существуют хорошо задокументированные риски, связанные с предвзятостью современного ИИ, которые необходимо устранить, новые риски, связанные с ИИ, в настоящее время слишком плохо определены, чтобы их можно было полностью устранить с помощью политики, поэтому исследователи и разработчики должны взять на себя инициативу. Однако как для существующих, так и для новых случаев можно предпринять шаги для подготовки к этим рискам.
Подходы к управлению рисками, используемые в страховании, финансах и других сферах бизнеса, обычно фокусируются на риске как продукте вероятности того, что что-то произойдет, и последствий этого события, измеряемых в долларах. Это хорошо работает в тех областях, где результаты можно легко преобразовать в доллары, есть результаты, которые легко поддаются количественной оценке, а наборы данных достаточно полны, чтобы производить надежные оценки вероятностей.
Подходы к управлению рисками, используемые для борьбы с текущими угрозами, скорее всего, потребуется пересмотреть, чтобы учесть непредвиденные возможности, которые может предоставить ИИ.
К сожалению, ни один из этих критериев не относится к рискам ИИ. Вместо того, чтобы думать о рисках как о вероятности и последствиях, в условиях, когда количественная оценка затруднена, риски можно рассматривать как комбинации угроз, уязвимостей и последствий. Такой подход используется в США Федеральным агентством по чрезвычайным ситуациям для подготовки к стихийным бедствиям, Агентством кибербезопасности и безопасности инфраструктуры при оценке способов защиты критической инфраструктуры, а также Министерством обороны для снижения угроз.
Уникальные риски ИИ сегодня в значительной степени не учитываются из-за их новизны, но ситуация меняется. 5 июля 2023 года OpenAI объявила о создании группы «Сверхсогласование» для устранения экзистенциальных рисков, связанных с ИИ. В контексте ИИ согласование — это степень, в которой действия системы ИИ соответствуют намерениям дизайнера. Этот акцент на исследованиях мировоззрения для сверхразума — отличное начало, но кажется слишком узким, и его можно было бы расширить.
Другие исследователи ИИ подчеркивают проблемы, связанные с расизмом, сексизмом и другими предубеждениями в существующих системах ИИ. Если систему ИИ нельзя спроектировать так, чтобы она была защищена от расизма или сексизма, как можно спроектировать ИИ так, чтобы он соответствовал долгосрочным интересам человечества? Поскольку компании вкладывают средства в исследования выравнивания, они также могут сделать упор на устранение этих хорошо известных, но сохраняющихся предубеждений в своих системах искусственного интеллекта.
В США обеспокоены тем, что ИИ вызовет хаос на выборах 2024 года
Последние несколько месяцев показали, насколько убедительными могут быть изображения, созданные искусственным интеллектом.
Команда губернатора Флориды Рона ДеСантиса опубликовала сфабрикованные изображения Трампа во время его пребывания на посту президента, обнимающего Энтони С. Фаучи.
Трамп, в свою очередь, поделился пародией на высмеиваемый запуск кампании ДеСантиса, в котором голоса, сгенерированные искусственным интеллектом, имитируют губернатора-республиканца, а также Илона Маска, Дика Чейни и других. А Республиканский национальный комитет выпустил рекламу, наполненную фальшивыми видениями антиутопического будущего при президенте Байдене.
В апреле Республиканский национальный комитет выпустил рекламу, полностью иллюстрированную с помощью искусственного интеллекта.
Плохая новость заключается в том, что нет никакой гарантии, что раскрытие информации станет нормой. Член палаты представителей Иветт Д. Кларк представила законопроект, который потребует раскрытия информации, идентифицирующей контент, созданный ИИ, в политической рекламе.
Национальный комитет Демократической партии и их коллеги, координирующие предвыборные гонки на уровне штатов и на местном уровне, должны пойти дальше, чем просто раскрытие информации, предлагая кандидатам указывать такие материалы во всех своих сообщениях, включая сбор средств и информационно-разъяснительную работу.
Партийные комитеты также должны рассмотреть возможность полного исключения некоторых видов использования.
В идеале кампании вообще должны воздерживаться от использования ИИ для изображения ложных реалий — в том числе, скажем, для изображения города, преувеличенно наполненного преступностью, для критики действующего мэра или для создания разношерстной группы нетерпеливых сторонников. По общему признанию, аналогичные эффекты могут быть достигнуты с помощью более традиционных инструментов для редактирования фотографий. Но вероятность того, что ИИ превратится во все более искусного иллюзиониста, а также вероятность того, что плохие актеры будут использовать его для огромной аудитории, означает, что крайне важно сохранить мир, в котором избиратели могут верить в то, что они видят.
Партийные комитеты должны вместе заняться этим нормотворчеством, подписав пакт, доказывающий, что достоверность информации на выборах не является вопросом партий. А честные кандидаты должны по собственной воле воздерживаться от нечестных выходок. Однако на самом деле им потребуется толчок со стороны регулирующих органов. У Федеральной избирательной комиссии уже есть строгий запрет на выдачу себя за кандидатов в предвыборной рекламе. Недавно агентство зашло в тупик, пытаясь выяснить, распространяется ли это право на изображения ИИ.
Есть много причин для беспокойства о том, что распространение ИИ сделает с демократией в США. Работа платформ по искоренению дезинформации стала еще более важной сейчас, когда можно рассказывать лучшую ложь стольким людям за такие небольшие деньги — и это становится все более трудным. Конгресс работает над широкой системой регулирования ИИ, но на это уйдут месяцы или даже годы.
ИИ в Китае
За последнее десятилетие Китай заложил прочную основу для поддержки своей экономики ИИ и внес значительный вклад в ИИ во всем мире. Индекс искусственного интеллекта Стэнфордского университета, который оценивает достижения ИИ во всем мире по различным показателям в исследованиях, разработках и экономике, ставит Китай в тройку лидеров по глобальному развитию ИИ.
Сегодня ИИ широко используется в Китае в сфере финансов, розничной торговли и высоких технологий, на долю которых в совокупности приходится более трети рынка ИИ в стране
В сфере технологий, например, лидеры Alibaba и ByteDance, известные в Китае, стали известны своими персонализированными потребительскими приложениями на основе искусственного интеллекта. На самом деле, большинство приложений ИИ, которые на сегодняшний день получили широкое распространение в Китае, относятся к отраслям, ориентированным на потребителя, благодаря крупнейшей в мире базе интернет-потребителей и возможности взаимодействовать с потребителями новыми способами для повышения лояльности клиентов, доходов, и рыночные оценки.
В ближайшее десятилетие в Китае появятся огромные возможности для роста ИИ в новых секторах, в том числе в тех, где расходы на инновации и НИОКР традиционно отставали от мировых аналогов: автомобилестроение, транспорт и логистика; производство; корпоративное программное обеспечение; здравоохранение и науки о жизни.
В этих секторах мы видим кластеры вариантов использования, в которых ИИ может создавать экономическую ценность на сумму более 600 миллиардов долларов в год. (Чтобы представить масштаб, валовой внутренний продукт в 2021 году в Шанхае, самом густонаселенном городе Китая с населением почти 28 миллионов человек, составил примерно 680 миллиардов долларов).
Для раскрытия всего потенциала этих возможностей ИИ обычно требуются значительные инвестиции — в некоторых случаях гораздо большие, чем могут ожидать руководители, — по нескольким направлениям, включая данные и технологии, которые будут лежать в основе систем ИИ, подходящие кадры и организационное мышление для создания этих систем, и новые бизнес-модели и партнерства для создания экосистем данных, отраслевых стандартов и правил.
Где в Китае ИИ может принести наибольшую пользу в будущем?
Это несколько секторов: автомобилестроение, транспорт и логистика, которые в совокупности, как ожидается, принесут большую часть — около 64 процентов — возможностей в размере 600 миллиардов долларов; производство, которое даст еще 19 процентов; корпоративное программное обеспечение, на долю которого приходится 13 процентов; а также здравоохранение и науки о жизни — 4 процента возможности.
Наш анализ показывает, что в каждом секторе возможности создания стоимости сосредоточены только в двух-трех областях. Как правило, это те области, в которых инвестиции частных и венчурных фирм были высокими за последние пять лет, и были представлены успешные доказательства концепции.
Идеи Шанхайской конференции
Всемирная конференция по искусственному интеллекту (WAIC) открылась в Шанхае 6 июля 2023 года. Китайские правительственные чиновники выступили единым фронтом в продвижении амбиций страны в области развития ИИ, несмотря на угрозу потенциальных новых технологических ограничений со стороны правительства Соединенных Штатов.
Заместитель министра промышленности и информационных технологий Китая Сюй Сяолань заявил в программной речи на конференции, что страна движется к разработке полной цепочки создания стоимости ИИ, которая охватывает «умные чипы и алгоритмы для промышленности. конкретные большие языковые модели (LLM)».
Она сказала, что правительство Китая увеличит свою поддержку отечественной индустрии искусственного интеллекта, которая, по оценкам, в настоящее время насчитывает более 4300 компаний.
Вторя этому заявлению, секретарь Коммунистической партии Шанхая Чен Цзинин сказал в своей презентации, что финансовый мегаполис уже поощряет ИИ «инновации алгоритмов, разработку чипов и языковых наборов данных». Он добавил, что Шанхаю удалось привлечь новые предприятия и таланты в сфере ИИ.
Оптимизм, выраженный этими двумя китайскими правительственными чиновниками, подчеркивает большую ставку страны на ИИ как на главный катализатор преобразования местной промышленности и подпитки падающей экономики страны.
В своем годовом отчёте о развитии искусственного интеллекта нового поколения (2022-2023 гг.) Служба экономической информации Китая — профессиональная организация при государственном информационном агентстве Синьхуа — сообщила, что сектор технологий искусственного интеллекта страны уже вышел на мировой уровень, что составляет около 16% компаний по всему миру, которые вовлечены в эту технологию.
В статье, опубликованной в июне 2023 года в People’s Daily, официальной газете Центрального комитета Коммунистической партии Китая, говорится, что генеративный ИИ находится на пути к тому, чтобы стать неотъемлемой частью рабочего места и повседневной жизни людей, что приведет к глубокие изменения в обществе, стимулирующие экономический рост и приводящие к новой промышленной революции.
В статье «Жэньминь жибао» также говорится, что на сегодняшний день китайские учреждения запустили не менее 79 LLM с более чем 1 миллиардом параметров, что является мерой размера и сложности модели.
LLM — это алгоритмы искусственного интеллекта с глубоким обучением, которые могут распознавать, обобщать, переводить, прогнозировать и генерировать контент, используя очень большие наборы данных. Они представляют собой технологию, используемую для обучения чат-ботов с искусственным интеллектом, например ChatGPT от OpenAI.
Заместитель председателя правления Huawei Technologies Кен Ху Хоукунь, который также является председателем правления технологического гиганта из Шэньчжэня, сказал, что компания пытается решить текущее узкое место «вычислительной мощности», которое препятствует развитию ИИ в Китае.
Правительство США в августе 2022 года ввело запрет на экспорт в Китай определенных продуктов от поставщиков чипов Advanced Micro Devices и Nvidia Corp, которые имеют почти монополию на графические процессоры (GPU), используемые для обучения систем искусственного интеллекта. Эти ограничения препятствуют прогрессу страны в различных передовых приложениях, от разработки LLM до автономного вождения.
Тем не менее, Ху указал, что Huawei помогла разработать около половины существующих LLM, разработанных в Китае, с помощью решения компании Ascend для центра обработки данных, представляющего собой кластерную сеть для крупномасштабного обучения моделей ИИ.
Тем временем соучредитель SenseTime Шон Тан Сяоу заявил в своей презентации на открытии WAIC, что китайские ученые внесли свой вклад в глобальное развитие технологий машинного обучения и крупных моделей ИИ.
Амбиции Китая в области искусственного интеллекта могут столкнуться с новым ударом, поскольку, как сообщается, правительство США рассматривает возможность ограничения доступа китайских компаний к американским службам облачных вычислений, что помешает Amazon Web Services и Microsoft Corp использовать возможности передовых чипов искусственного интеллекта для своих клиентов на материке.
Вашингтон также работает над новыми правилами, которые ограничат потоки капитала и информации в чувствительные технологии в Китае, такие как полупроводники и искусственный интеллект.
Потенциальный запрет США на доступ китайских фирм к американским службам облачных вычислений может оказаться следующим серьезным препятствием для усилий страны по развитию LLM, по словам руководителя отрасли WAIC. Он сказал, что обучение систем искусственного интеллекта требует значительных вычислительных мощностей.
Огромный спрос Китая на передовые полупроводники для новых проектов разработки ИИ уже создал быстрорастущий рынок контрабандных графических процессоров, таких как устройства A100 и H100 от Nvidia.
Новые правила регулирования
13 июля 2023 года Китай выпустил самые подробные правила в отношении моделей генеративного искусственного интеллекта (ИИ), подчеркнув здоровый контент и «основные социалистические ценности», поскольку Пекин стремится контролировать развертывание услуг в стиле ChatGPT.
В соответствии с предварительными правилами, опубликованными совместно семью китайскими регулирующими органами во главе с Администрацией киберпространства Китая, которые вступят в силу 15 августа 2023 года, все услуги генеративного контента ИИ, включая текст, изображения, аудио и видео, предоставляемые населению Китая, будут подлежать к новым правилам.
По сравнению с более ранним проектом, опубликованным в апреле 2023 года с целью получения отзывов общественности, новые правила имеют более благосклонный тон в отношении новой технологии, а власти обещают «принять эффективные меры для поощрения инновационного развития генеративного ИИ».
Китай ещё не разрешил какой-либо отечественной фирме развернуть услуги в стиле ChatGPT для широкой публики, а Ernie Bot из Baidu и Tongyi Qianwen из Alibaba Group Holding либо все еще находятся в пробном режиме, либо предназначены только для коммерческого использования.
Между тем, ChatGPT от OpenAI и Bard от Google остаются недоступными в Китае, а ссылки на эти зарубежные модели быстро блокируются. Новые правила, хотя и предназначены для тщательного контроля над развитием генеративного ИИ, скорее всего, обеспечат отечественным разработчикам более четкий путь для вывода своей продукции на массовый рынок.
Китайские регулирующие органы заявили, что будут проявлять «инклюзивное и разумное» отношение к генеративным услугам ИИ и внедрять «градуированный» подход к регулированию. К другим регулирующим органам, участвующим в проекте правил, относятся Национальная комиссия по развитию и реформам, Министерство образования, Министерство науки и технологий, Министерство промышленности и информационных технологий, Министерство общественной безопасности и Управление вещания Китая.
В соответствии с новыми правилами поставщики услуг генеративного ИИ должны: «придерживаться основных социалистических ценностей» и обязуются не создавать никакого контента, который «подстрекает к подрыву государственной власти и свержению социалистической системы, ставит под угрозу национальную безопасность и интересы, наносит ущерб имиджу страны, подстрекает к отделению от страны, подрывает национальное единство и социальную стабильность, пропагандирует терроризм, экстремизм, национальную ненависть и этническую дискриминацию, насилие, непристойность и порнографию».
В более общем плане модели ИИ и чат-боты не должны генерировать «ложную и вредную информацию».
Разработанные в Китае чат-боты и модели искусственного интеллекта уже имеют встроенные функции, гарантирующие, что создаваемый контент не содержит нежелательной информации. Например, Чжун Хунъи, председатель 360 Security Technology, постарался описать в презентации функцию самоцензуры чат-бота, показав, что если пользователь вводит «деликатное слово», чат-бот немедленно прекращает разговор.
Что касается разработки алгоритмов и выбора данных для обучения, регулирующие органы Китая требуют, чтобы поставщики услуг избегали любой дискриминации по признаку этнической принадлежности, вероисповедания, страны, региона, пола, возраста, профессии и состояния здоровья, а также уважали права интеллектуальной собственности.
Согласно новому постановлению, Китай также поощряет «инновационное применение генеративной технологии искусственного интеллекта», а также «позитивный, здоровый контент».
Постановление согласовывает развитие ИИ с политическими и экономическими приоритетами Китая в соответствии с его постановлением 2021 года об алгоритмах рекомендаций и постановлением 2022 года о глубоком синтетическом контенте, который Пекин требует маркировать как «синтетически созданный».
Ся Хэйлун, юрист шанхайской юридической фирмы Shen Lun, сказал, что «основной регулятивный подход в новом регламенте согласуется с общей регулятивной концепцией Китая в отношении киберпространства» с упором на соответствие контента и соблюдение основных ценностей, защиту личной информации, а также обязательство предотвращать нарушения.
В то же время Ся отметил, что Китай пытается регулировать общедоступные услуги ИИ, а не технологии ИИ как таковые. Например, услуги на основе ИИ, предназначенные для промышленного или внутреннего корпоративного использования, не подпадают под действие закона, сказал Ся.
Новые правила соответствуют Закону Китая о кибербезопасности, Закону Китая о безопасности данных и Закону о защите личной информации.
Новые правила также предусматривают, что поставщики услуг генеративного ИИ должны прекратить свою деятельность и сообщить о незаконных действиях, если обнаружат, что пользователи используют ИИ для создания нелегального контента на своих платформах.
Поставщики услуг ИИ также должны установить барьеры, чтобы предотвратить зависимость несовершеннолетних от таких услуг.
ИИ в России
За технологиями искусственного интеллекта (ИИ) — будущее, это не менее важно, чем атомные проекты в СССР. Об этом заявил Президент России Владимир Путин 19 июля 2023 года во время совещания с участниками заседания наблюдательного совета АНО «Россия — страна возможностей».
В тот же день 19 июля 2023 года Президент России в режиме видеоконференции провел совещание с членами Правительства РФ во вопросам развития искусственного интеллекта.
На совещании отмечалось, что руководители регионов до 1 сентября 2023 года обязаны завершить работу по разработке стратегий, предусматривающих внедрение ИИ. Развитие искусственного интеллекта – это одно из ключевых условий достижения технологического суверенитета страны. Искусственный интеллект сегодня – это технологии распознавания лиц для обеспечения безопасности, предиктивная аналитика для прогнозирования урожая, внесения удобрений, производственных процессов, распознавание снимка в медицине, компьютерное зрение в производственных системах и многое другое.
В России растёт объём рынка продуктов, в которых используются такие технологии: в 2022 году он увеличился на 18 процентов и достиг почти 650 миллиардов рублей. Но в отличие от многих других стран в России есть компании, которые создают решения мирового уровня.
При этом Правительство РФ работает по повестке искусственного интеллекта реализуя национальную стратегию до 2030 года.
Основным инструментом реализации стратегии стал федеральный проект «Искусственный интеллект». Он включает три основных направления работы.
Первое – это развитие фундаментальной и прикладной науки. На базе ведущих вузов и научных организаций созданы и работают шесть исследовательских центров. Они ищут подходы, как обучить нейросети на меньшем количестве данных, как повышать скорость вычислений с помощью машинного обучения, создают новые методы и архитектуры формирования нейросетей. На эти исследования из федерального бюджета выделено более пяти миллиардов рублей в течение четырёх лет. Показателем эффективности центров является то, что они готовят решения по внедрению искусственного интеллекта для бизнеса. В центрах привлекли на это почти 2,5 миллиарда рублей частного финансирования от ведущих российских компаний.
Вторая задача – это подготовка кадров. С 2022 года более ста вузов запустили программы бакалавриата и магистратуры для подготовки специалистов по искусственному интеллекту. Сейчас по ним обучаются три тысячи человек, а с 2024 года будет обучаться в четыре раза больше студентов, то есть мы доведём до 12 тысяч человек.
Есть также подготовка и в рамках дополнительного профессионального образования. В 2022 году обучение по востребованным специальностям в сфере искусственного интеллекта – от аналитика данных до руководителя проектов – прошли почти две тысячи человек, столько же учится сейчас, и из бюджета компенсируется 90 процентов затрат на такое обучение.
Для вовлечения молодёжи в развитие технологий искусственного интеллекта проводятся хакатоны среди молодых IT-специалистов. За два года участие в них приняли более 20 тысяч человек. Что такое хакатон? Это когда компании предлагают, скажем так, практические проблемы, которые надо решить, объявляют некий премиальный фонд, и команды специалистов из числа молодёжи в течение суток, двух суток предлагают свои решения.
Третья задача федпроекта – это грантовая поддержка компаний-разработчиков. За последние два года на это было направлено семь миллиардов рублей. Во-первых, через Фонд содействия инновациям поддерживаются небольшие проекты: там компании получают гранты до 50 миллионов рублей. Уже профинансированы проекты более 750 компаний.
Все разработчики, которых поддерживает Правительство РФ, включаются в специально созданный реестр инновационных компаний. Это позволяет отслеживать этапы их развития и привлекать инвесторов. Сейчас в реестре более 1000 стартапов, у которых решения – с использованием искусственного интеллекта.
Расширять сферы применения ИИ помогают также экспериментально-правовые режимы. На сегодняшний день установлено шесть режимов в сфере беспилотного транспорта. Три из них обеспечили запуск легковых и грузовых наземных беспилотников: это уже известный опыт беспилотных грузоперевозок Москва – Питер и то, что в Иннополисе, и в Москве сейчас вышло на дороги такси в беспилотном режиме. Ещё три режима установлены для тестирования авиабеспилотников. Их будут использовать для сельхозработ и мониторинга лесных пожаров.
18 июля 2023 года подписано постановление Правительства РФ, которое даст ход ещё одному эксперименту – уже в сфере телемедицины.
Подготовлен законопроект, который позволит учитывать вопросы, связанные с ответственностью за причинение вреда в результате использования искусственного интеллекта, а также урегулирует вопросы защиты прав на результаты интеллектуальной деятельности, которые созданы с использованием таких технологий.
На совещании обращено внимание на системообразующее развитие для отрасли.
Во-первых, разработчики искусственного интеллекта должны получить доступ к обезличенным данным – весь искусственный интеллект строится на обработке больших массивов данных. Это условия развития всей отрасли. Это ключевой вопрос, по которому необходимо ускорить работу.
Второй момент – внедрение искусственного интеллекта должно стать одним из условий предоставления господдержки компаниям. С 2024 года будет протестирован подход в сельском хозяйстве, транспорте, промышленности и здравоохранении, то есть в тех отраслях, где у действительно наработана уже большая практика решений. То есть если компании будут получать какую-то субсидию из бюджета выше определённой суммы, они должны будут у себя внедрить то или иное решение с использованием искусственного интеллекта. Тем самым поощряется спрос на все эти разработки.
Третье – обеспечивается интеграция инструментов национального проекта «Производительность труда» в программы развития искусственного интеллекта.
В рамках «пилота» Федеральный центр компетенций проанализировал 80 решений, отобрал десять для внедрения на предприятиях – участниках национального проекта.
При этом Федеральный центр компетенций готов выступить таким заказчиком и агрегатором функциональных требований и помогать внедрению искусственного интеллекта.
Четвёртый момент – искусственный интеллект должен активнее внедряться в образовательные программы вузов. В Минобрнауки разработан специальный учебный модуль, специальная программа. Внедрение этого модуля носит рекомендательный характер. Предлагается сделать внедрение модуля обязательным для таких образовательных программ, особенно там, где у нас есть IT-кафедры, их сейчас тоже много создаётся.
Пятый момент – на базе вузов будут открыты новые исследовательские центры. В дополнение к действующим шести до конца 2023 года по конкурсу предлагаем отобрать ещё не менее шести для поддержки уже на 2023–2026 годы.
Какие задачи необходимо дополнительно решать Правительству РФ уже следующем этапе развития ИИ и какие вызовы возникают?
Первое – необходимо формировать условия для создания собственных вычислительных мощностей, причём на будущее – кратно больших, чем то, что у имеется, в том числе в виде крупных вычислительных кластеров. В перспективе, с использованием отечественных комплектующих.
Второй момент – поддержать учёных и молодые компании грантами на доступ к этим вычислительным мощностям, с тем чтобы они могли активно разрабатывать и обучать сложные нейросети с использованием большего количества параметров, а также совершенствовать их архитектуру, потому что отчасти правильной архитектурой можно компенсировать некий недостаток вычислительных мощностей.
Третий момент – в России существует большая государственная программа «Научно-технологическое развитие» – более триллиона рублей финансируются на научные исследования. Предложено дополнительно вместе с Академией наук провести мониторинг, насколько мы в научных исследованиях страны используются технологии искусственного интеллекта. Нам кажется, там тоже есть большой потенциал повышения эффективности научных исследований.
Четвёртый момент. Необходимо разграничить ответственность за разработку и за последующее применение, использование больших сложных систем искусственного интеллекта, больших сложных нейросетей. Крайне важно, чтобы разработчик понимал периметр своей ответственности, чтобы он не отвечал – условно – за все продукты, которые искусственный интеллект может выдать и сгенерировать – какие-то изображения, тексты и так далее. Иначе начнутся какие-то ограничения в сфере моделей, введение внутренних цензоров. Это резко снижает эффективность апробации, внедрения и самих нейросетей.
Все эти задачи предлагается интегрировать в Национальную стратегию развития искусственного интеллекта, которую Президент России поручил обновить, сейчас эта работа завершается. Благодаря решения о продлении федерального проекта «Искусственный интеллект», включению его в формирующийся нацпроект «Экономика данных» сейчас возможно заложить все мероприятия, которые необходимы, и обеспечить их финансированием.
Рассмотреть итоговую конфигурацию варианта нацпроекта планируется на стратегической сессии под руководством Председателя Правительства, она запланирована в сентябре 2023 года.
Главные усилия сейчас направлены на создание законодательной базы, которая позволит обеспечить доступность больших данных для разработчиков искусственного интеллекта. На площадке Госдумы сейчас завершена доработка поправок, которые Правительство РФ внесло ко второму чтению совместно с профильными управлениями Администрации, профильным комитетом Госдумы.
Работа была сконцентрирована на вопросах обеспечения защиты прав и интересов граждан при обработке больших данных и применении искусственного интеллекта. Сейчас коммерчески оборот больших данных в России не регламентирован, хаотично осуществляется, потому что понятных и прозрачных правил нет.
В рамках уточнённых поправок ко второму чтению согласованы процедуры обезличивания данных, определен порядок, как будут формироваться датасеты, необходимые для этого машинного обучения. Достигнута договоренность о тех правилах, на которых внешние разработчики получат доступ к этим данным, для того чтобы начать обучать свои нейросети.
При этом подготовленными поправками предусматривается прямой однозначный запрет на обработку больших данных, если это создаёт риски причинения вреда гражданам, обороне и безопасности.
Доступ внешних разработчиков к большим данным будет возможен только в случае подтверждения отсутствия в них сведений, которые позволят идентифицировать гражданина, то есть мы исключаем любую персонификацию обрабатываемых больших данных.
Внешний доступ к большим данным также будет запрещён иностранным гражданам и компаниям с доминирующим иностранным участием.
Получилась конструкция, которая исходит из безусловной защиты интересов и прав граждан и при этом обеспечивает доступ разработчиков к большим данным.
Для организации работы с большими данными создаётся на платформе «Гостех» государственная информационная система. В неё будут загружаться обезличенные датасеты – как от органов власти, так и от бизнеса, и уже к этим наборам данных будет предоставлен доступ авторизованным разработчикам нейросетей, которые соответствуют необходимым требованиям.
Эти обезличенные наборы данных нельзя будет скачать, выгрузить, забрать из этой информационной системы. Можно будет на них тестировать, настраивать алгоритмы, обучать нейросети. Это не создаёт угрозы этим данным.
Определены пять главных приоритетов внедрения искусственного интеллекта в системе госуправления.
Первое – искусственный интеллект должен упростить получение госуслуг. Идеальный вариант, как будет обеспечено: искусственный интеллект даёт возможность в диалоге, задавая человеку простые вопросы, получать конкретно ответы, на что он [человек] может рассчитывать в его конкретном случае, какие действия он должен совершить, чтобы получить ту или иную услугу, какие документы представить. Это существенно упростит получение госуслуг.
На портале госуслуг уже запустили робота, который отвечает на вопросы пользователей фактически автоматически. В день 1,5 миллиона вопросов пользователей он обрабатывает в автоматическом режиме. Качество 85 процентов ответов пользователи считают хорошим. Этот робот фактически в восьми случаях из десяти автоматически даёт подсказки человеку, что ему нужно делать для того, чтобы получить ту или иную услугу.
Идеально, когда это вообще осуществляется голосом, когда можно голосом обозначить вопрос, и вам робот ответит, что вам нужно делать, или запишет к врачу. Такой «пилот» идёт вместе с «Яндексом» и со Сбербанком, с их голосовыми помощниками – это такие специальные станции, – когда уже можно будет голосом получать государственные услуги.
Второе направление – это большая рекомендательная система, которая будет помогать регионам планировать своё территориальное развитие, определять места, где лучше построить детский сад, школу, поликлинику с учётом плотности населения, транспортной доступности, социальной инфраструктуры, которая есть рядом.
Эта же система будет предлагать варианты, как оптимизировать движение транспорта, как оптимально выстроить маршруты общественного транспорта, какое должно быть расписание с учётом реальной загрузки и трафика, который есть на транспортных коммуникациях.
Третье направление –это использование искусственного интеллекта в медицине.
В 2023 году запускается большой «пилот». Уже сформированы в регионах большие массивы электронных медицинских изображений, где как раз уже проведена разметка и выявлены заболевания. Это те самые датасеты, на которых можно учить алгоритмы делать это автоматически, фактически мы будут «скармливаться» им уже размеченные снимки, где диагностировано заболевание, а дальше нейросети смогут на новых снимках помогать врачу, обращая внимание там, где есть потенциальные признаки таких заболеваний, то есть работа врачей в данном случае станет легче. С врачей снимается рутинная нагрузка.
Четвёртое направление – это анализ спутниковых снимков: незаконная вырубка леса, вовлечение земель в сельхозоборот, эффективность засевов. Искусственный интеллект позволяет выявлять объекты, которые построены, но не зарегистрированы, соответственно, с них не платятся налоги.
Пятое направление, – климатическая повестка. В России накоплен очень большой массив данных наблюдения за погодой, который за многие десятилетия в Росгидромете сформирован. Создается большой датасет, который позволит тестировать новые технологии прогноза погоды, которые будут уже значительно оперативнее, точнее, качественнее.
На совещании предложено, что за вопросы ИИ должны отвечать те заместители руководителей ведомств, которые сейчас отвечают за цифровую трансформацию. Тогда внедрение цифровых технологий, работа с данными и искусственный интеллект будут в одних руках, и это будет всё между собой увязано.
С 1 января 2023 года в Налоговом кодексе действует стимулирующая мера для компаний – внедрять российские решения с искусственным интеллектом. Компании расходы, которые тратят на внедрение российских решений ИИ, могут списывать с коэффициентом 1,5, то есть фактически уменьшая немного налог на прибыль. Уже 17 российских решений зарегистрировано, по 28 решениям сейчас рассматриваются заявки. Бизнес начинают активно пользоваться этими мерами, внедрять эти решения и получать соответствующие льготы.
Завершая совещание Президент России Владимир Путин отметил, что по многим направлениям использования цифровых решений Россия уже находится в числе глобальных лидеров:
«Есть ограничения, и без определённых связей, контактов и наработок на мировом уровне нам не обойтись. Тем не менее, обеспечивая настоящий технологический суверенитет нашей страны, нужно думать именно о собственных ресурсах. В этой связи отмечу несколько конкретных мер.
Первое – напомню, что мы договорились обеспечить до 2030 года государственную поддержку исследовательских центров в области искусственного интеллекта. И здесь нужно отработать все нормативные, организационные и финансовые вопросы, в том числе в федеральном бюджете на 2024–2026 годы должны быть заложены средства на финансирование таких исследовательских центров. Если этого не будет, то и движения вперёд не будет.
Второе – необходимо расширить охват компаний с государственным участием, которые используют или планируют задействовать механизмы искусственного интеллекта в своей работе. Прошу это рассматривать как прямое поручение. Нужно поработать с этими компаниями. Да, безусловно, потребуются изменения в корпоративные стратегии цифровой трансформации – да, конечно. Прошу Правительство предметно заняться этим вопросом с компаниями, как я уже сказал.
Третье. Ключевой элемент, основа работы искусственного интеллекта, мы это хорошо все знаем, – это обработка больших массивов данных. Я уже не раз говорил, подобные сведения, которые касаются наших граждан, должны быть обезличены и надёжно защищены. С учётом этих обязательных требований нужно организовать доступ к данным со стороны участников рынка. И прошу Правительство совместно с Государственной Думой рассмотреть и принять такой законопроект в осеннюю сессию текущего года.
Четвёртое. У нас запущены экспериментальные правовые режимы в сфере цифровых инноваций, однако их механизмы требуют, безусловно, совершенствования, в том числе на законодательном уровне. Нужно дополнительно упростить доступ к таким режимам, а также ввести страхование ответственности за возможный ущерб, причинённый при использовании искусственного интеллекта, мы об этом тоже много раз уже говорили. Эту работу также прошу завершить в период осенней сессии парламента.
Пятое. Как уже отметил, технологии искусственного интеллекта несут прямую экономическую выгоду, всем это понятно. Тем не менее на начальном этапе их внедрение идёт не очень активно. Лидеры у нас есть, но за ними «скамеечка запасных» небольшая. Мы с вами уже договаривались, как надо поступить в этой ситуации, а именно: включить требования по обязательному использованию искусственного интеллекта для компаний, которые планируют получить субсидии из федерального бюджета. Хотите субсидии – пожалуйста, развивайтесь в этом направлении.
Шестое. Важнейший вопрос – это подготовка специалистов, которые работают с цифровыми технологиями. Всем вузам страны уже направлен обновлённый образовательный модуль «Системы искусственного интеллекта», он рекомендован к включению в обязательные программы. Думаю, можно сделать более решительный шаг сегодня и объявить такой модуль обязательным».
*Деятельность Meta* (соцсети Facebook* и Instagram*) запрещена в России как экстремистская.
https://zavtra.ru/blogs/iskusstvennij_intellekt_vnov_vishel_v_chislo_naibolee_obsuzhdaemih_mirovih_problem


























