
- Введение

Что такое настоящий LegalTech, а что скрывается под громкими рекламными слоганами? Почему никому из IT-разработчиков не удалось создать действительно прорывной и функциональный продукт, близкий к цифровому юристу? Какой подход позволил нам решить данные задачи и существенно приблизиться к созданию настоящего юридического искусственного интеллекта?
Какова роль практикующих юристов в процессе разработки инструментов автоматизации?
В данной статье мы хотим поделиться с Вами результатами многолетних исследований в области искусственного интеллекта и предоставить ответы на эти вопросы.
Disclaimer: мы не критикуем существующие инструменты, а говорим о том, что для решения обозначенного круга задач требуется качественно новый подход к разработке.
1. LegalTech в России
Наша компания более 15 лет успешно работает на рынке консалтинговых и юридических услуг. Обладая значительным юридическим опытом решения самых нестандартных кейсов и сложных проектов в России и за рубежом, мы посвятили не один год научному исследованию и практическим разработкам в области цифровых технологий и перспектив их применения в профессии. Несколько лет назад мы задались вопросом: почему юридический рынок обделен инструментами автоматизации? Анализ предлагаемых продуктов позволил прийти к следующим результатам.
Мы, как профессиональные юристы, активно следим за развитием сферы LegalTech и за решениями, которые предлагаются на рынке в качестве прорывных продуктов, способных, по заявлениям создателей, изменить традиционное представление о работе юриста. Но на самом деле в качестве LegalTech на отечественном рынке распространяются решения, которые очень далеки от содержательной автоматизации юридической функции и позволяют решать локальные задачи, не связанные с творческой и экспертной юриспруденцией. В то время, как инженеры активно применяют в повседневной работе решения, выполняющие сложные расчеты и рутинные операции, а сотрудники финансового сектора используют цифровые платформы для построения финансовых моделей и оценки рисков, все, что есть у юристов — чуть более продвинутые поисковые сервисы и шаблоны документов.
Весь доступный инструментарий для юриста сегодня это:
- конструкторы документов, работающие на основе типовых и унифицированных шаблонов, в которых любое отклонение от формы требует ручной правки;
- сервисы проверки контрагента, осуществляющие агрегацию общедоступной информации из публичных реестров (ЕГРЮЛ/ЕГРИП, Федресурс, КАД и др.), которые редко позволяют найти ценную информацию;
- системы подбора судебной практики и справочно-правовые системы, осуществляющие базовый поиск по ключевым словам, фразам, тегам в открытой базе судебных решений и НПА, которые предоставляют все документы, содержащие искомое слово без учета контекста и др.;
- системы управления проектами, задачами и документами (различные BPM/ERP/ECM-системы, заточенные на автоматизацию биллинга, учет времени и контроль за ресурсами).
Данные инструменты ни на шаг не приближают нас к автоматизации творческой и экспертной юриспруденции. Они, безусловно, облегчают работу юриста, но только в вопросах поиска информации, а не в ее интеллектуальной обработке с точки зрения юридической логики. Практикующие юристы высокой квалификации согласятся с нами, что если бы можно было предлагать клиентам шаблонные договоры, в которые встроены актуальные даты, суммы и наименования объектов, то профессии юриста уже бы не было. Ценность юриста заключается в его способности предвидеть ситуацию на несколько шагов вперед и предлагать нестандартные решения в пользу клиента с минимальными рисками и издержками с точки зрения права.
Мы однозначно можем сказать, что при существующем уровне развития технологий юридический рынок в России (и, скорее всего, в мире) не имеет полноценных решений, способных заменить юриста даже начальной квалификации и автоматизировать хоть в сколько-нибудь значимой части юридическую функцию.
2. Особенности предметной области
Прежде чем перейти к анализу технологической стороны вопроса необходимо понять особенности предметной области. Работа любого юриста-эксперта связана с документами. Данные и документы разнородны и имеют собственные отличительные особенности. Задача профессионального юриста при работе с документами заключается в том числе в правовой оценке их содержания, квалификации отношений между субъектами, выявлении правовых и финансовых рисков для представляемой стороны и выработке предложений по их минимизации или в регламентации существующих отношений между хозяйствующими субъектами.
Например, к юристу обратился клиент, который столкнулся с недобросовестным поведением контрагента и требует защитить его интересы. Задачами юриста являются:
- запросить и (или) собрать необходимые документы (договоры, акты, письма и все иные материалы, имеющие отношение к делу) и установить значимые юридические факты;
- оценить их под призмой действующего законодательства и практики его применения (понять правовую природу отношений и определить круг правовых норм, подлежащих применению);
- предложить варианты решения проблемы и собственные рекомендации, после — реализовать выбранный вариант.
Это только один из примеров, с которыми сталкивается юрист ежедневно. При последовательном решении каждой отдельно взятой задачи проявляется профессионализм и экспертные навыки, которые формируются по мере работы юриста и накопления опыта. Одна из значимых компетенций юриста — это умение видеть в письменных документах все юридические факты, выделять наиболее значимые и соотносить их с нормами права для поиска возможных решений. Именно поэтому одной из ключевых и первостепенных задач, которую необходимо решить для создания действительно функционирующих инструментов автоматизации юридической работы, является обучение машины смысловому понимаю текста на уровне юриста-профессионала. Речь идет о полноценном семантическом анализе юридических текстов.
При обращении к вопросам автоматизации юридической функции и создания полноценного юридического искусственного интеллекта мы считаем, что без применения глубоких лингвистических технологий эти задачи решить не получится. Это, прежде всего, связано с необходимостью научить программные инструменты понимать не только отдельные сущности (категории) в тексте, но и анализировать текст, выделять все возможные смыслы и проводить логические взаимосвязи в его содержании. В качестве подтверждения данного тезиса приведем следующие аргументы.
В первую очередь, при анализе документа юрист оценивает его содержание с точки зрения смыслов, которые в нем содержатся. Например, в тексте большинства уставов обществ с ограниченной ответственностью имеется следующий пункт, дублирующий п. 3 ст. 21 Федерального закона № 14-ФЗ от 08.02.1998 г.: «Доля участника Общества может быть отчуждена до полной ее оплаты только в той части, в которой она уже оплачена». Применяя экспертные юридические знания мы можем извлечь следующие смысловые блоки из данного предложения:
- У участника Общества есть доля.
- Доля участника общества может быть отчуждена.
- Доля участника общества может разделяться на части.
- Часть доли может быть отчуждена.
- Участник Общества вправе осуществить отчуждение доли или части доли участника Общества.
- Доля участника Общества оплачивается участником.
- Доля участника Общества может быть оплачена не полностью.
- Часть доли участника Общества может быть оплачена.
- Часть доли участника Общества может быть не оплачена.
- Отчуждение неоплаченной части доли участника Общества запрещено.
- Отчуждение оплаченной части доли участника Общества разрешено и др.
Подобный уровень детализации смыслового содержания документов с помощью машинных инструментов невозможно добиться без воссоздания юридической «картины мира» путем разработки экспертных семантических концептов, созданных в тесном взаимодействии с погруженными в предметную область (как в теорию, так и в практику) специалистами.
Кроме того, с точки зрения внутренней структуры, документы, используемые в юриспруденции, могут быть классифицированы следующим образом:
- высокоструктурированные документы, имеющие установленную законом строгую форму и упорядоченное содержание (выписки и справки из публичных реестров, документы на бланках строгой отчетности, управленческая документация по ОКУД и др.);
- слабоструктурированные документы, имеющие, как правило, шаблонную форму, но содержащие некоторые творческие элементы (банковские выписки и др.);
- неструктурированные документы, не имеющие однородной формы и содержания и характеризующиеся высоким уровнем уникальности содержания (договоры, корпоративные акты, процессуальные документы, юридические заключения, меморандумы и др.).
И если для машинной обработки высокоструктурированных документов сложные лингвистические решения не требуются, то для слабоструктурированных и неструктурированных документов, которых в области права большинство, технологии NLP (Natural Language Processing) являются единственным инструментом, способным справиться с данной задачей.
Итак, определив приоритетные задачи для создания юридического искусственного интеллекта, мы приступили к анализу рынка и тестированию существующих инструментов NLP. Результаты исследования представлены в Главе 2 настоящей статьи.
2.1. Чат-боты и цифровые ассистенты
Пару слов также нужно сказать про ставших недавно популярными цифровых помощников, чат-ботов, ассистентов и т. п. Безусловно, с приходом Alexa, Siri и Алисы множество аспектов бизнеса и нашей повседневной жизни кардинально поменялись:
- подавляющее большинство задач планирования («поставь встречу в календарь») и поиска информации («найди год выпуска фильма») решается без участия человека;
- наверное, самый большой эффект на себе пока ощутила сфера поддержки клиентов, где личное общение со специалистом все чаще становится доступным только для премиального сектора.
В свете такого взрывного роста возникает большой соблазн создать робота-юриста (как end-to-end решение):
- записать ответы юриста на ТОП-100/1000 самых частых вопросов, составить подробный FAQ, описать все возможные жизненные ситуации и т. п.;
- «загрузить» в нейронную сеть всю имеющуюся судебную практику, судебные решения;
- как результат — получить робота, который сможет (например, при помощи deep learning) соотнести запрос пользователя с ответом юриста (судебным прецедентом, решением), который был дан ранее в похожей ситуации.
Такая идея далеко не нова, но все попытки ее реализации за всю мировую историю права неизменно заканчивались неудачей. Причина в следующем: практикующий юрист почти каждый день сталкивается с новой уникальной задачей, которая требует творческого подхода. В связи с этим технологии чат-ботов и ассистентов мы не расцениваем как элемент LegalTech/Legal AI, поскольку они имеют сугубо опосредованное отношение к автоматизации юридической функции.
Наше субъективное мнение: применение технологий цифровых ассистентов, чат-ботов в сферах экспертной деятельности — крайне рисковое мероприятие:
- ущерб от некорректных действий традиционного чат-бота, например, в сфере поддержки клиентов является номинальным: в случае некорректной работы можно получить недовольного клиента, плохой отзыв и т. п.;
- если ошибается чат-бот в сфере, где необходимы экспертные знания (например, юриспруденция, медицина, строительство) — ущерб может быть непредсказуемым и фатальным.
При этом не составляет особого труда предугадать логику законодательного регулирования. Если цифровые ассистенты и чат-боты будут допущены до экспертной сферы, то, скорее всего, на уровне закона будет установлено, что за все рекомендации и действия ассистентов и чат-ботов их разработчики несут полную ответственность.
3. Анализ существующих подходов и инструментов
Исследованиям вопросов в области лингвистики и технологий NLP мы посвятили большое количество времени в том числе в рамках рабочих встреч и обсуждений подходов с представителями научного сообщества. Нельзя не оценить их вклад в развитие инструментов обработки текста, которые в настоящее время показывают хорошие практические результаты. Мы благодарны представителям научного сообщества за бесценный опыт, которым они поделились с нами и внимание, проявленное к нашим разработкам. Прежде всего мы имеем в виду следующие коллективы:
- ИТМО (Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики) и, в частности, Руководителя международной лаборатории «Интеллектуальные методы обработки информации и семантические технологии», доцента факультета программной инженерии и компьютерной техники Дмитрия Муромцева, а также его коллег — Любовь Ковригину и Ивана Шилина: под руководством Д. Муромцева был адаптирован для русского языка синтаксический парсер, созданный в Стэндфордском университете для применения на англоязычных текстах (подробнее о тестировании парсера Stanford — в разделе 3.2.3.3.);

- Лабораторию компьютерной лингвистики ИППИ РАН им. А.А.Харкевича (Институт проблем передачи информации Российской академии наук) и, в частности, научных сотрудников Леонида Иомдина и Ивана Рыгаева, под руководством которых был создан синтаксический парсер ЭТАП (и версия ЭТАП-4), применяемый для русского языка (подробнее о тестировании ЭТАП — в разделе 3.2.3.2.).

В России направление NLP развивается во многом благодаря энтузиазму и многолетней работе ученых, осуществляющих разработки в области процессинга русскоязычного текста в условиях ограниченного бюджета, а также отсутствия частных и государственных инвестиций, способных финансировать масштабные исследовательские проекты. Несмотря на эти обстоятельства, данными научными коллективами были достигнуты огромные практические результаты в области процессинга текста на русском языке, которые заслуживают уважения.
По нашему мнению, обозначенная проблема отсутствия финансовой поддержки и инвестиций в научные разработки технологий NLP в России является одним из факторов, сдерживающих развитие данной области. Государственная поддержка таких проектов позволила бы совершить существенный прорыв в области семантики и синтаксического парсинга, а также достигнуть огромных результатов.
Далее мы предлагаем рассмотреть существующие подходы и инструменты в области обработки текста на русском языке с практической стороны.
3.1. Существующие подходы и коммерческие продукты
В области NLP на отечественном рынке присутствует ряд коммерческих решений, которые предлагают универсальный функционал по процессингу русскоязычных текстов. Однако среди данных продуктов отсутствуют профильные решения, ориентированные на юристов и способные удовлетворить потребности предметной области в полном объеме.
Совокупно данные продукты могут быть разделены на две группы. Первая группа представляет собой решения, функционал которых обеспечивается за счет многочисленного набора правил, которые формулируются лингвистами и специалистами из предметной области. Наиболее известными системами являются решения от ABBYY, Pullenti, Megaputer и ряда других др. Разработчиками данных решений предлагается проведение лингвистического анализа неструктурированных текстов посредством выделения именованных сущностей (Named Entity Recognition), применения правил морфологии, синтаксиса, семантики и иных процедур обработки (как правило, такие правила описываются в проприетарном закрытом формате). Стоит оговориться, что в таких системах могут применяться элементы машинного обучения, но они играют второстепенную роль.
Принципиальный недостаток таких решений кроется в подходе — реализация функционала путем создания отдельных правил приводит к необходимости вырабатывать десятки/сотни тысяч правил для отдельно взятой области, что неизбежно приводит к возникновению противоречий. Классический пример:
- для фразы: «студент проходил обучение в МГУ имени М.В.Ломоносова»;
- правила поиска организаций дадут результат — «МГУ имени М.В.Ломоносова»;
- правила поиска имен (ФИО) дадут результат — «М.В.Ломоносов»;
- для разрешения данной (и каждой похожей) ситуации нужно вручную создавать специальное правило-исключение.
Кроме того, одно изменение или ошибка может потребовать пересмотра значительной части правил.
Вторая группа — решения, основанные на применении нейронных сетей, обученных на корпусе текстов. Наиболее яркими представителями являются DeepPavlov, FRED и др. В отличие от первой группы продуктов использование машинного обучения позволяет уйти от необходимости разработки правил анализа текста и их правки при изменениях в предметной области, однако для подготовки обучающего датасета требуется профессиональная разметка сотен тысяч образцов документов каждой используемой категории. В настоящее время существующие модели предобучены на корпусе текстов из общедоступных источников: художественной литературы, текстов в сети (wikipedia) и др., что не позволяет полноценно использовать их при обработке юридических текстов, обладающих собственной спецификой. Обучение же на корпусе юридических документов осложнено отсутствием в открытом доступе достаточного количества уникальных образцов в связи с конфиденциальным характером содержания реальных правовых документов.
Именно поэтому в настоящее время нет коммерческих проектов, созданных на основе ML/DL, где в качестве обучающего датасета присутствует достаточное количество юридических текстов. Тем не менее многие крупные компании, обладающие собственной обширной базой документов, предпринимают попытки создания инструментов для внутреннего пользования.
3.2. Тестирование отдельных инструментов NLP
Общеизвестен факт, что русский язык во многих аспектах — один из самых сложных языков, особенно когда дело касается профессиональной лексики. Юридические тексты объединяют в себе не только специфическую терминологию, но и формализм, сложную синтаксическую структуру, характеризующуюся наличием множества оборотов (сложносочиненных и сложноподчиненных предложений, причастных и деепричастных оборотов и др.).
Исследуя и подбирая инструменты для решения задачи процессинга юридических текстов на русском языке, мы столкнулись с рядом проблем. Для понимания сложности задачи приведем два примера предложений:
- Стоимость товара составляет десять тысяч рублей.
- Согласно пункту 4 Правил безвозмездные целевые взносы предоставляются субъектом оптового рынка на цели выделения из соответствующих бюджетов субъектов Российской Федерации субсидий на возмещение гарантирующим поставщикам, реализующим электрическую энергию (мощность) покупателям на розничных рынках, расположенных в территориально изолированных технологических системах и (или) на территориях, технологически не связанных с Единой энергетической системой России и технологически изолированными территориальными электроэнергетическими системами, а также гарантирующим поставщикам (энергосбытовым (энергоснабжающим) организациям), реализующим электрическую энергию (мощность) покупателям на розничных рынках, расположенных на территориях неценовых зон оптового рынка, недополученных доходов в связи с доведением цен (тарифов) на электрическую энергию (мощность) до базовых уровней цен (тарифов) на электрическую энергию (мощность) в соответствующем периоде регулирования в соответствующем субъекте Российской Федерации. (Решение Верховного Суда РФ от 22 марта 2019 г. № АКПИ18-1182)
Очевидно, что предложения по типу второго примера чаще используются в юридических текстах, чем по типу первого, что и порождает проблемы в реализации процессинга.
Кроме того, для русского языка неприменимы инструменты, созданные для англоязычных текстов. Причина тому кроется в критических различиях в данных языках. Тогда как английский язык является аналитическим, русский язык обладает главным образом свойствами синтетического языка. Из этого следует ряд принципиальных отличий между ними. Английский язык имеет фиксированный порядок слов, обеспечивающий структурную связность текста, тогда как в русском языке структура формируется при помощи множества грамматических морфем (приставок, суффиксов, флексий).
Для понимания приведем следующий пример: «В 2019 году совершена притворная сделка, в соответствии с которой имущество было отчуждено в пользу аффилированного лица мужа члена Совета директоров, фиктивный развод с которым состоялся годом ранее». В данном предложении придаточная часть может относится к нескольким сущностям: «аффилированному лицу», «мужу», «члену Совета». В английском языке этот вопрос разрешился бы за счёт близости главной и зависимой частей.
Английскому языку присуще также обязательное наличие в предложении подлежащего и сказуемого, тогда как русский язык характеризуется возможностью пропуска не только одного из главных членов предложения, но и зачастую слов, смысл которых предполагается, применяя такие фигуры речи, как эллипсис (пропуск слов с возможностью контекстуального восстановления). Например: «На собрании председательствующий представил аудиторское заключение, ревизор – решение суда», в котором повторяющийся глагол «представил» опускается во второй части и реализуется с помощью пунктуации.
Все это свидетельствует о сложности и уникальности русского языка, особенно с учетом особенностей профессиональной терминологии юристов. Текущий уровень развития NLP, к сожалению, не позволяет нам сформировать лингвистические универсалии, позволяющие совершать сложные логические операции (анализ, синтез, генерация и вывод) над текстами всех областей человеческих знаний. Более того в настоящее время нет готовых программных решений по процессингу русского языка даже для крайне узких предметных областей по отдельности, не говоря даже о юридических текстах, которые сочетают в себе как профессиональную лексику, так и общеупотребительные конструкции и терминологию из других сфер.
Технологии NLP строятся на трёх основных направлениях лингвистики: морфологии, синтаксисе и семантике. Поиск решений в области морфологического анализа для русского языка уже не вызывает острых вопросов: есть несколько готовых качественных инструментов в области морфологии, а также открытых библиотек (например, natasha/yargy). С синтаксисом дела обстоят несколько иначе. Мы исследовали множество парсеров, созданных для русского языка и адаптированных к нему. У всех есть свои преимущества и недостатки. Решение задачи семантического анализа юридических текстов также осложнено рядом проблем. Подробнее об этом расскажем ниже.
3.2.1. Семантический анализ
3.2.1.1. DeepPavlov
Исследования и разработки с применением семантики направлены на решение многих задач NLP: от глубинного машинного перевода до диалоговых систем и программных решений по генерации готовых текстов. Изучая научные наработки и готовые open-source модели, мы пришли к выводу, что интенсивнее всего семантическая область NLP на русском языке развивается в сфере систем с естественно-языковым интерфейсом, способным принимать вопросы и отвечать на них на естественном языке (Question-answering system, QA-системы). Однако и в сфере QA-систем отсутствуют профильные решения для юристов.
Одна из наиболее эффективных существующих моделей — DeepPavlov. Данная модель основана на Google BERT (и ряде других моделей) и является открытой программной библиотекой разговорного AI для создания виртуальных диалоговых ассистентов и универсального анализа текста.
Для первого теста мы выбрали предложение осложненное сочинительной, подчинительной связями, перечислениями, уточнениями, аббревиатурами, сокращениями, числами, производными союзами и предлогами: «В соответствии со ст. 46 Конституции РФ и гл. 24 АПК РФ граждане и организации вправе обратиться в суд за защитой своих прав и свобод с заявлением об оспаривании решений, действий органов государственной власти, органов местного самоуправления, должностных лиц, государственных или муниципальных служащих, в результате которых, по мнению указанных лиц, были нарушены их права и свободы или созданы препятствия к осуществлению ими прав и свобод либо на них незаконно возложена какая-либо обязанность или они незаконно привлечены к ответственности».
Тест проводился путем поочередных вопросов системе:
- «Чьи действия можно оспорить?»;
- «Чьи решения можно оспорить?»;
- «Какие действия можно оспорить?»;
- «Какие решения можно оспорить?».

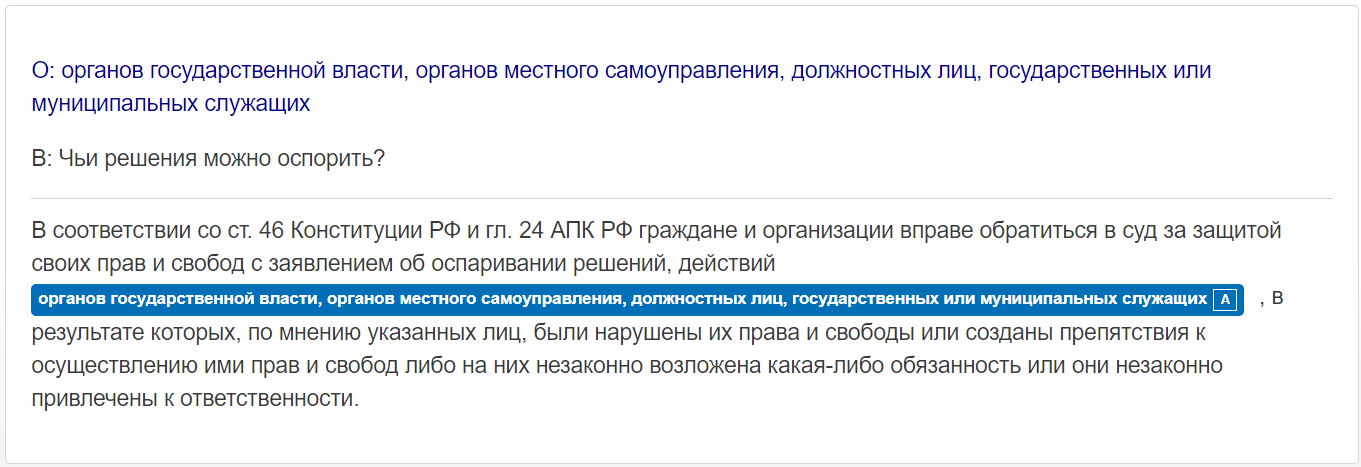
Наглядно видно, что вопрос «Чьи действия/решения можно оспорить?» не вызывает трудностей у системы: придаточная часть «органов государственной власти…» относится к однородным членам предложения одинаково, вне зависимости от последовательности этих слов в предложении. Очевидно, вопрос предполагает синтаксическую связь «действий», «решений» со словом/словами в форме родительного (притяжательного) падежа и, вероятно, множественного числа.
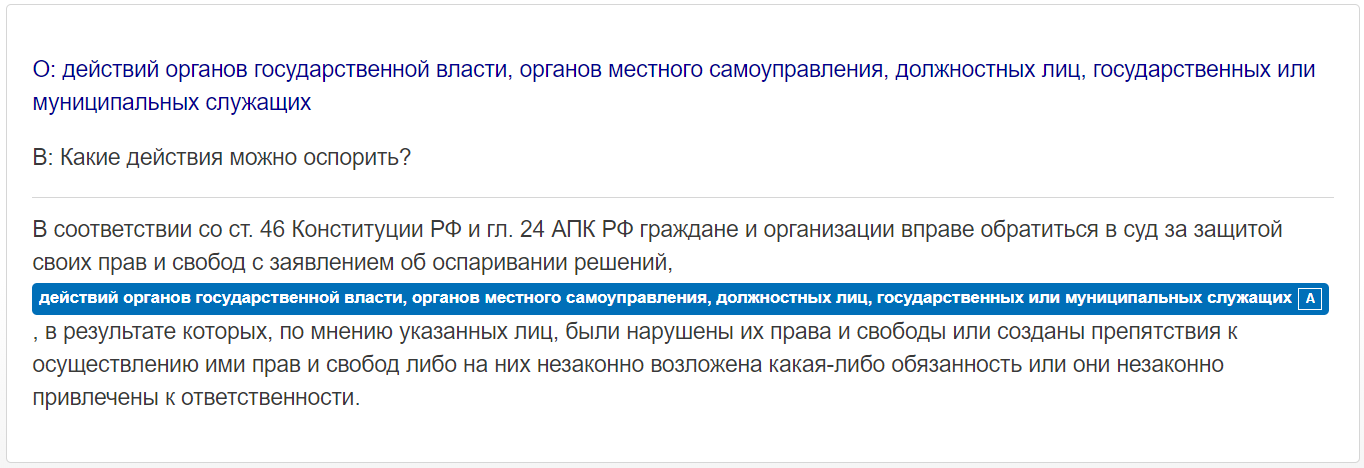

Однако, перефразируя тот же вопрос, мы получаем другой результат. Когда вопрос формулируется более абстрактно, последовательность слов в предложении начинает иметь гораздо большее значение, чем его синтаксическая структура, что не соответствует смыслу предложения.
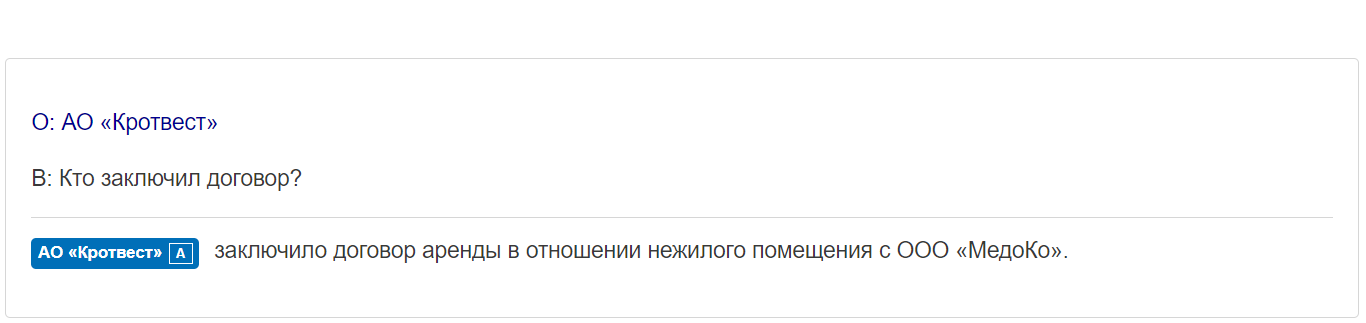
В рамках второго теста мы попытались определить субъектный состав и объект договора из более простого предложения: «Между ООО «Кротвест и ООО «МедКо» заключен договор аренды в отношение нежилого помещения».
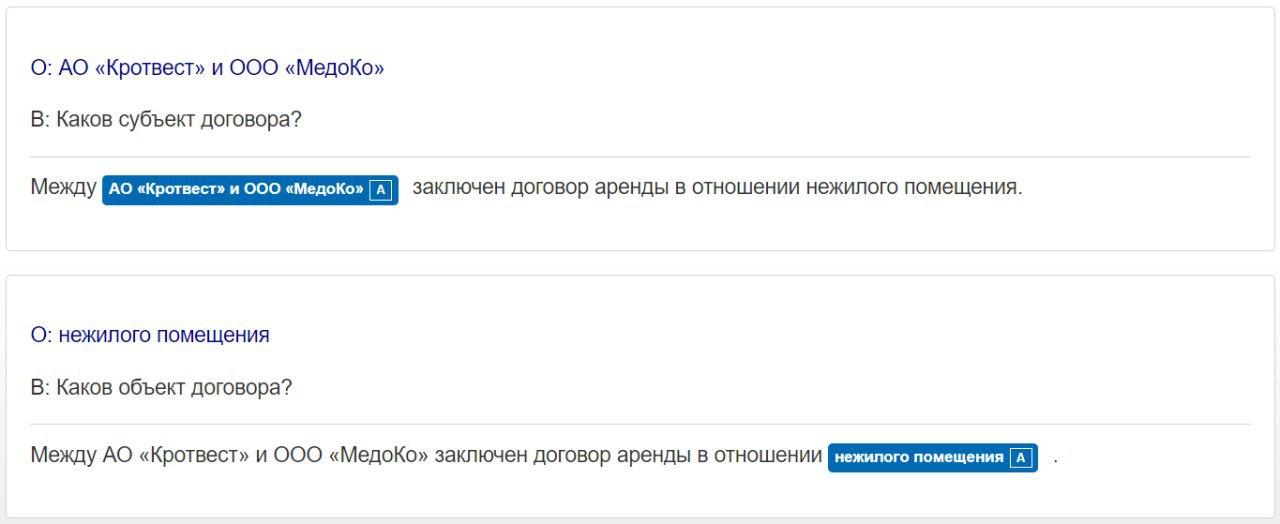
Как видно из результатов, система DeepPavlov успешно определила объект и субъектный состав договора из простого предложения. Усложнение задачи и изменение последовательности слов в предложении на входе снова демонстрирует жёсткую привязку семантического анализа к синтаксису и последовательности слов.

Субъект определяется корректно только том случае, когда стороны записаны подряд и напрямую связаны синтаксически (в данном случае предлогом «между» и соединительным союзом «и»). Стоит отметить, что с точки зрения юридической логики оба предложения содержат абсолютно идентичные смыслы: субъектами являются обе компании. Однако в зависимости от формулировки вопроса ответ определяется неустойчиво.

Для третьего теста мы проверили возможность вычленять факты, используя конверсивы (слова, выражающие отношения к одну и тому же событию с разных углов зрения). За основу было взято предложение с именованными сущностями (организация и лицо) и глаголом «продать». Модель хорошо идентифицировала вопросы, лексически дублирующие текст предложения.


Когда же в вопросе применялся конверсив «купить», ответ снова привязывался к синтаксической зависимости вопроса и предложения, а не к семантическому концепту в целом.

Аналогичные операции были проделаны на более простом предложении: «Зоя продала Лене коляску».



В данном тесте модель успешно идентифицировала как объект, так и субъектный состав отношений.
Помимо приведенных примеров мы провели множество других тестов QA-модели DeepPavlov, в том числе на предложениях, не связанных с юриспруденцией. В результате можно сказать, что модель показывает хорошие результаты при постановке вопросов, синтаксически и лексически близких к предложению на входе и, потенциально, может быть использована в качестве поисковой системы для документов большого объёма. Однако для качественного контекстуального анализа и, как следствие, выделения точных данных и значимых смыслов из текста с помощью данной модели видится невозможным. А ведь именно эти задачи представляют особую важность для инструментов, применяемых в юриспруденции.
3.2.1.2. FRED machine reader for the Semantic Web
Ещё одним инструментом семантической обработки текста, привлёкшим наше внимание, является семантический парсер FRED. Архитектура FRED построена на применении нейронных сетей, принципов фреймовой семантики и онтологического подхода, в результате чего анализируемый текст систематизируется путем выстраивания семантических связей между элементами и множеством существующих онтологий.
Система успешно выделяет семантические группы и предоставляет ссылки на используемые онтологии, что позволяет продолжить процессинг текста через онтологические отношения. Предлагаем более детально рассмотреть достоинства и недостатки данного подхода на примерах.
В качестве исходных данных для первого теста мы выбрали следующие простые предложения:
«ООО «Лесник» продало Друнову В.С. партию деревянных слэбов».

«Зоя продала Лене коляску».

Оба примера связаны с отношениями купли-продажи объекта. С точки зрения гражданского права РФ договор купли-продажи включает в себя сторон (продавец и покупатель), объект (объект гражданского оборота, отчуждаемый продавцом в собственность покупателя) и предмет (действия, совершаемые сторонами для достижения желаемого правового результата, а именно — продавец обязуется передать имущество в собственность покупателя, а покупатель — принять объект и оплатить его стоимость).
Рассмотрим, как факты, связанные с продажей, структурируются с помощью FRED:
- выявлено событие «Продажа» (в графе оно не предполагает обратного события — «Покупка», однако такая возможность должна подразумеваться отношениями в онтологиях);
- событие имеет Агента (продавца) и Реципиента (покупателя);
- событие имеет «Тему» продажи (продукт) с его атрибутами, иными словами — материальный объект отношений.
Стоит отметить, что имена физических лиц и наименований организаций во FRED определяются так же неустойчиво (сравните связи агента и реципиента в первом и втором предложении): если во втором предложении «Зоя» и «Лена» соотнеслись с соответствующими именами в онтологии (иначе говоря, были распознаны в качестве имён), то в первом предложении Агент «ООО Лесник» и Реципиент «Друнов В.С.» не соотносятся с классами онтологии вовсе, что говорит о неидентификации наименований организаций в качестве таковых.
Далее рассмотрим пример с синтаксической близостью сторон в предложениях о заключении договора на следующих примерах:
«ЗАО «СадыОгороды» заключило договор аренды нежилого помещения с И.С. Ивановым».
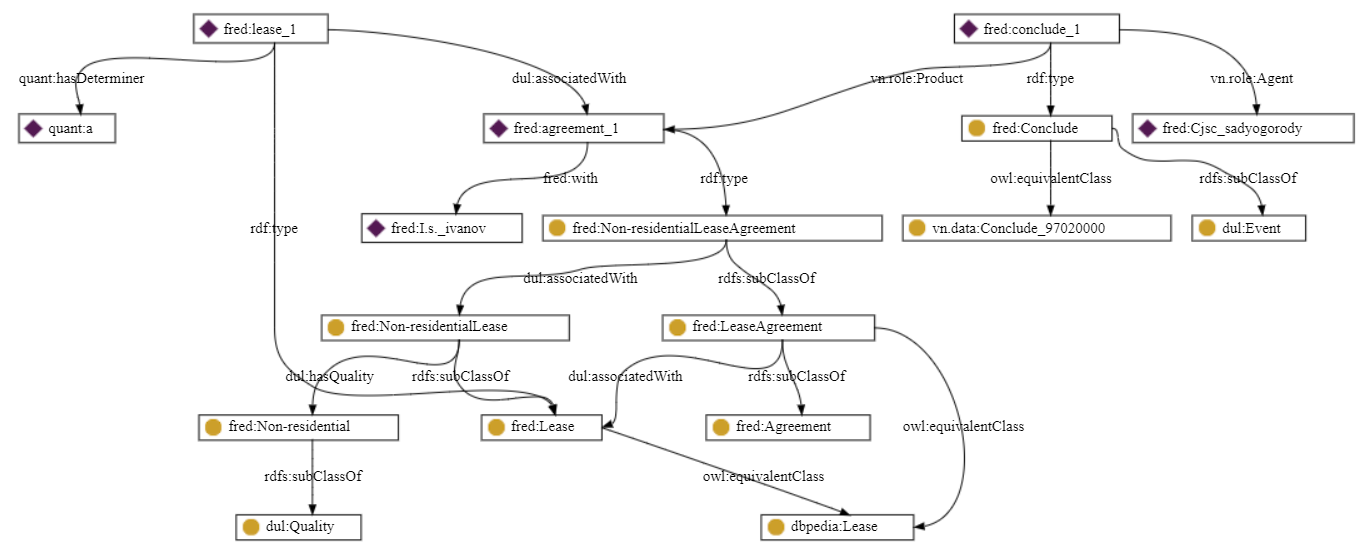
«ЗАО «СадыОгороды» и И.С. Иванов заключили договор аренды нежилого помещения».
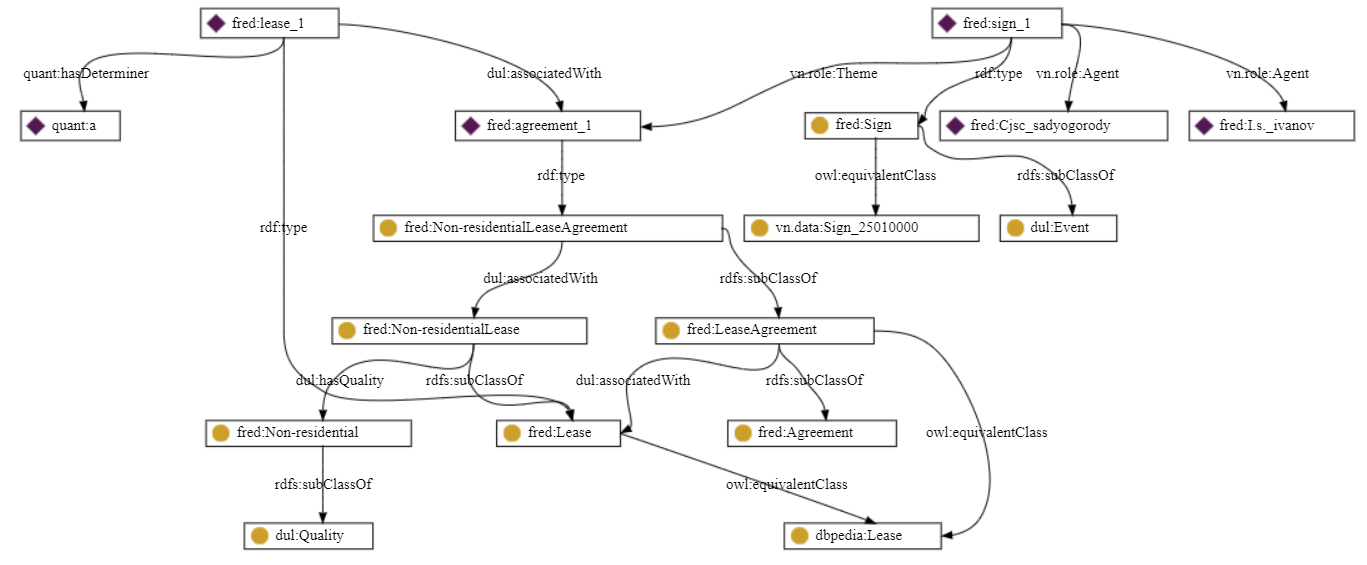
В первом примере на графе событие имеет только одну сторону (в качестве Агента идентифицировано «ЗАО СадыОгороды»). Второй же фактический Агент данного предложения «И.С. Иванов» ошибочно ассоциирован с событием через «Продукт» (договор) связью ‘с’ – «Договор ‘с’ И.С. Ивановым». С точки зрения семантики и юридической логики эта связь уместнее в случае «Договор ‘c’ правками (приложением; доп. соглашением и т.д.)». Во втором же примере на графе верно выделяются обе стороны договора («ЗАО СадыОгороды» «И.С. Иванов» имеют роль Агента).
Данные тесты наглядно демонстрируют наличие общей проблемы у FRED и DeepPavlov при семантическом анализе, связанной с сильной привязкой к синтаксису и последовательности слов в предложениях. FRED в сравнении с DeepPavlov, на первый взгляд, видится инструментом, позволяющим выделять факты и семантические связи между ними более конкретно. Однако, при детальном рассмотрении у данного подхода обнаруживаются те же проблемы, что и у DeepPavlov.
3.2.2. Named Entity Recognition (NER)
Еще один инструмент, который широко применяется в компьютерной лингвистике, — Named Entity Recognition (NER). Инструменты NER позволяют распознавать в тексте устойчивые именные сущности по типу таких структурированных данных: дата и время, суммы и числовые величины, адреса, наименования географических объектов, регистрационные и идентификационные номера, ФИО и наименования компаний и др., а также определять их принадлежность к той или иной группе или категории.
На тему подбора оптимальных для русского языка инструментов NER и библиотек уже написано некоторое количество статей. Вкратце стоит отметить, что на сегодняшний день существует множество хороших моделей, пока дело не доходит до русского языка… Здесь мы сталкиваемся с двумя основными проблемами: как правило, ограниченным количеством классов и/или rule-based системами, имеющими в перспективе некоторые ограничения в развитии и, как следствие, риски в их применении. Но готовых решений нет и, в сущности, не может быть без адаптации инструмента к предметной области и решаемым задачам.
Для применения NER в юридической сфере требуется высокая степень детализации и точности разметки ФИО и наименований организаций, классов документов, чисел, торговых марок, наименования объектов гражданского оборота и других сущностей. По своей сути классификация именованных сущностей должна быть построена юристами с учетом действующего правового режима. С точки зрения профессиональной логики такой классификатор должен включать в себя исчерпывающий и закрытый перечень участников оборота (физическое лицо, индивидуальный предприниматель, юридическое лицо с учетом всех организационно-правовых форм), объектов (недвижимое и движимое имущество с учетом всех разновидностей и др.) и должен быть сформирован по принципу — совокупность дочерних сущностей образует родительскую. Например, помещение, здание, земельный участок, морское судно и др. в совокупности образует категорию «недвижимое имущество», а недвижимое имущество в совокупности с движимым есть «вещь».
На практике же, существующие инструменты распознавания именованных сущностей содержат в себе классификаторы, адаптированные под универсальное применение без привязки к конкретной области знаний. Например, библиотека DeepPavlov предлагает следующие типы распознаваемых сущностей.
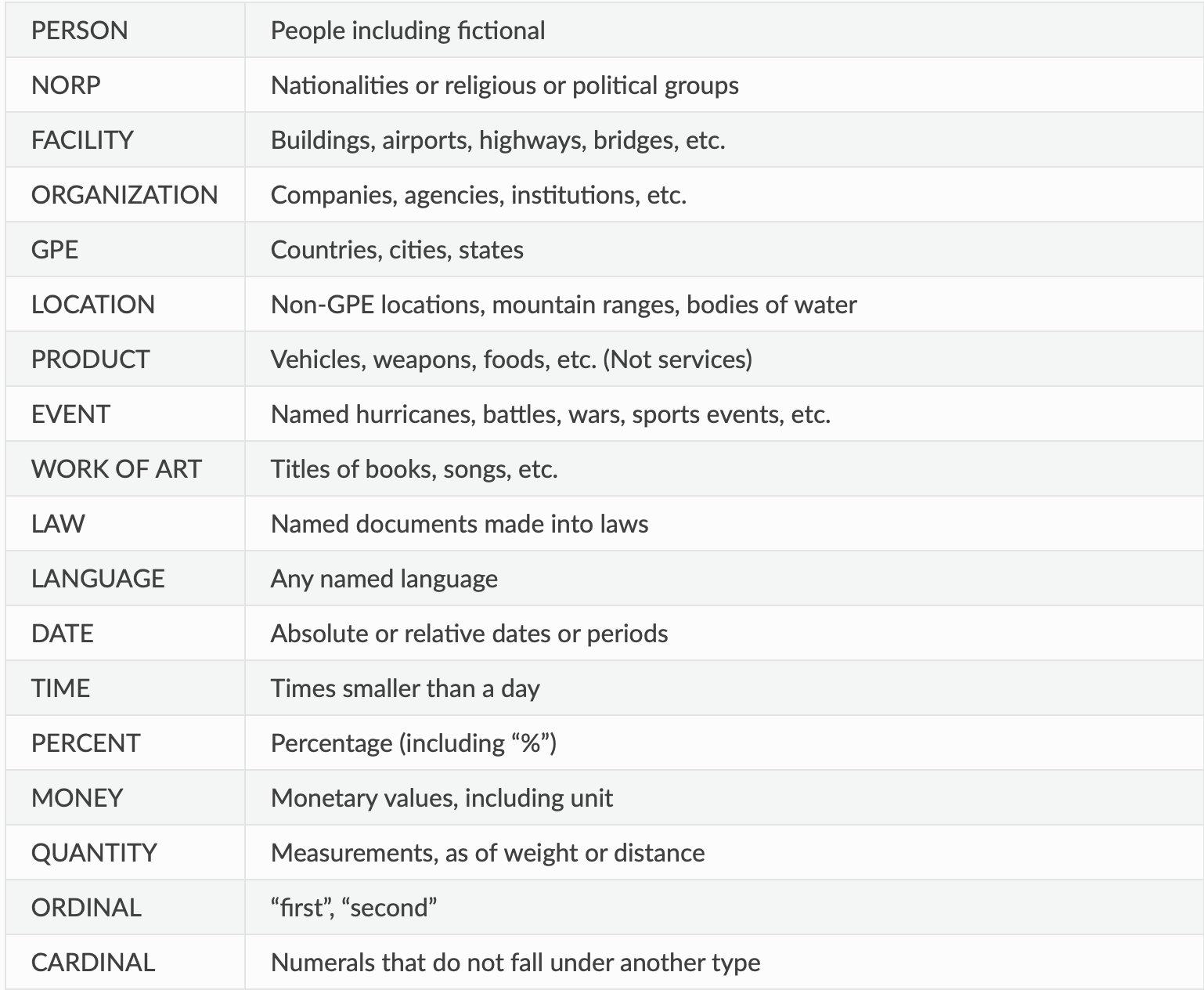
На первый взгляд, такая классификация представляется вполне разумной, так как во многом совпадает с логикой/форматом восприятия обычного человека. Однако если посмотреть на такую структуру глазами юриста-профессионала, то обнаруживается ряд существенных проблем:
- предлагается одноуровневая структура, которая не укладывается в рамки российского законодательства: в одну категорию «Facility» объединены все объекты материального мира, являющиеся по своей сути недвижимостью (здания, мосты и др.), а в «Product» — движимое имущество, не учитывая, что все эти объекты являются вещами;
- самостоятельной группой выступает «Work of art», включающая в себя произведения искусства (с точки зрения права — результаты интеллектуальной деятельности) и др.
Используемая в DeepPavlov классификация хорошо подходит для общих целей и воспроизводит некоторую верхнеуровневую группировку объектов и субъектов материального мира. Но такой подход полностью игнорирует фундаментальные основы российского права: особенности объектов гражданского оборота, субъекты правоотношений, их правовой статус и др. Книга в материальном понимании — это вещь, аналогично велосипеду, но которая одновременно является и произведением искусства, охраняемым как результат интеллектуальной деятельности.
По большому счёту, этот факт говорит о необходимости участия экспертов предметной области в построении классификатора «с нуля» в соответствии юридической базой знаний. При этом юристы имеют возможность фактически создать профессиональную таксономию (экспертное видение предметной области) под актуальные задачи.
Важность корректного распознавания именованных сущностей заключается в том, что именованные сущности являются фундаментом для семантического анализа текстов. При этом верно и обратное: семантический анализ способствует более точной разметке именованных сущностей, когда только из контекста возможно вычленить искомые атрибуты. Достаточно распространённый пример, иллюстрирующий необходимость использования глубокого контекстуального анализа, — эллипсис (пропуск элемента высказывания, легко восстанавливаемого в данном контексте), появляющийся в текстах ближе к середине-концу изложения. Например, тот случай, когда в первом абзаце говорится об «ИП Иванов И.С.», который должен быть идентифицирован в качестве индивидуального предпринимателя, а далее повествование содержит различные вариации той же сущности, в том числе «Иванов», который без контекстуального анализа будет размечен в качестве физического лица).
3.2.3. Синтаксический парсинг
Третьим важным инструментом процессинга текста выступает синтаксический анализ, выполняемый с помощью различных синтаксических парсеров. Синтаксический парсер представляет собой инструмент анализа предложений на основе его синтаксической структуры и представления данных в виде дерева зависимостей, выстроенного между словами. Выбор синтаксического парсера, очевидно, определяет работоспособность семантического анализатора, поскольку синтаксические связи (в т.ч. их тип и место) напрямую определяют результат семантической обработки.
Для исследования работоспособности синтаксических анализаторов на текстах юридического характера, имеющих структурную специфику (юридический стиль характеризуется инкорпорированием в сжатое повествование формальной информации типа наименования документов, паспортных данных и пр., аббревиатур, насыщенностью оборотами, приложениями, подчинительными и сочинительными связями, пояснениями и др.), нами был создана тестовая коллекция предложений разной степени сложности, взятых из реальных юридических документов. Предложения коллекции были дифференцированы и разбиты на три группы: простые предложения, предложения средней и высокой степени сложности. Для понимания сложности задачи приведем примеры каждой из группы предложений из тестовой выборки:
- Простое предложение: «Между Истцом и Ответчиком заключен Договор аренды от 01.08.2012 г. в отношении нежилого помещения».
- Предложение средней степени сложности: «Принимая во внимание вышеизложенное, Договор купли-продажи доли является ничтожным в силу статьи, поэтому не влечет юридических последствий за исключением тех, которые связаны с его недействительностью и недействителен с момента его совершения».
- Предложение высокой степени сложности: «Принимая во внимание вышеизложенное, Договор купли-продажи доли в размере 75% уставного капитала Общества от 26.10.2006 г., заключенный между Компанией Марс Систем и Закрытым акционерным обществом «Консалтинговая фирма «СТН МРТ», является ничтожным в силу ст. 168 ГК РФ, поскольку заключен с нарушением п.3 ст. 154 ГК РФ, поэтому не влечет юридических последствий за исключением тех, которые связаны с его недействительностью и недействителен с момента его совершения».
Мы проанализировали большинство доступных парсеров (ниже приведена основная их часть) на данной коллекции юридических предложений разной степени сложности и пришли к выводу, что качественный синтаксический парсинг на основе существующих инструментов возможен только для простых предложений и предложений средней степени сложности (с рядом оговорок). Парсинг предложений высокой степени сложности пока недоступен и требует существенных доработок
При тестировании парсинга предложений средней степени сложности был выбран следующий фрагмент: «В разъяснениях, данных в п. 16 Постановления пленума ВС РФ и Пленума ВАС РФ «О некоторых вопросах применения Федерального закона», указано на то, что выход участника из общества осуществляется на основании его заявления».
Подробности тестов различных синтаксических парсеров приведены ниже.
3.2.3.1. АОТ
Проект «Автоматическая обработка текстов» (АОТ) приостановил своё развитие несколько лет назад. Как заявляли его создатели, подход, используемый в АОТ, скорее можно назвать консервативным, чем революционным, поскольку общая идея, объясняющая сущность естественного языка, отсутствует. Максимально приблизить человеческий язык к современному компьютеру возможно только при помощи грамотной декомпиляции языковых механизмов. Тем не менее для нас было важно апробировать данную систему для сравнения её с грамматикой зависимостей, поскольку АОТ применяет грамматику непосредственно составляющих.

На скриншоте с результатами теста заметно, что не все слова и сокращения («ВАС РФ», «указано») в предложении имеют связи со словами и группами слов. «ВАС» и «РФ» должны быть связаны по типу «генит_иг», а «указано» должно объединиться с предложной группой «на то…» связью «кр_прч». Помимо этого большое количество именных, предложных и прочих групп не связаны друг с другом. К примеру, группа «выход участника» синтаксически связана с группой «из общества», что не следует из выведенного системой разбора.
Дело в том, что грамматика непосредственно составляющих с трудом перекладывается на структуру русского языка с его нефиксированной последовательностью слов в предложении, и, соответственно, предложение теряет значительное количество синтаксических связей, в том числе влияющих на смысл.
Отсюда следует, что главным минусом данного подхода является неполнота связей. Иначе говоря, некоторые токены остаются «в воздухе», что недопустимо при создании графа и дальнейшем семантическом анализе.
3.2.3.2. ЭТАП
ЭТАП – лингвистический процессор, разработанный сотрудниками ИППИ РАН. В его основе лежит теория «Смысл <=> Текст» И.А.Мельчука. Это система, главное предназначение которой – анализировать и синтезировать тексты, то есть преобразовывать тексты из их исходного вида в некоторое абстрактное представление, приближенное к представлению смысла, и обратно. Помимо этого главного предназначения, направленного на решение фундаментальной задачи моделирования естественного языка, имеется и прикладной аспект. Поскольку система умеет понимать и строить тексты, разумно попытаться использовать эту способность в каких-либо конкретных приложениях, способных принести конкретную пользу, например, для генерации юридических документов на основе входных данных.
Система является rule-based решением как в области синтаксиса, так и в области семантики.
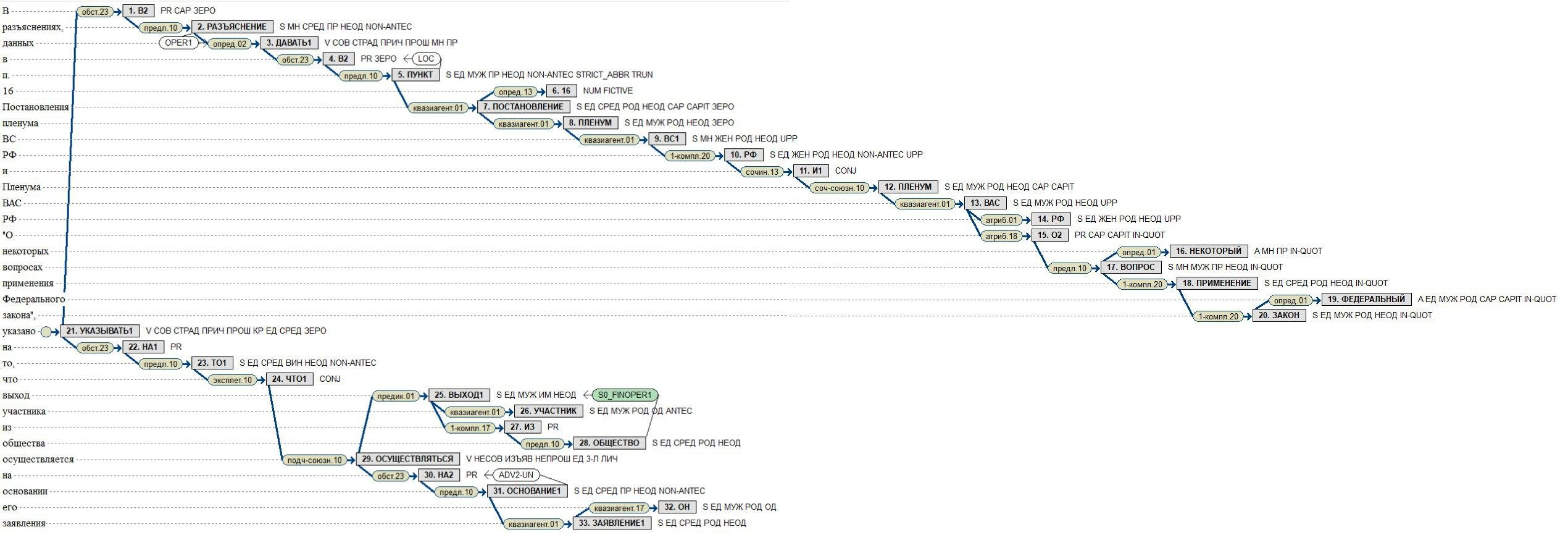
На результатах теста видно, что процессор ЭТАП с трудом усваивает длинные, осложнённые предложения: последовательно расположенные существительные в больших предложениях соотносятся друг с другом так же последовательно. Например, это распространяется на следующую часть предложения: «Постановления Пленума ВС РФ и Пленума ВАС РФ».
Сочинительная связь ‘conj’ должна связывать слова «Пленума» и «Пленума», а по результату процессинга соединяет подряд стоящие слова «РФ» и «Пленум». Подобные ошибки в дальнейшем могут сказаться на семантической логике связей. Также система дробит числовые показатели и, следовательно, находит новые несуществующие с точки зрения смысла связи.
К преимуществам ЭТАП можно отнести присутствие дополнительных лексических функций/связей, позволяющих более глубоко работать с семантикой на следующих этапах
3.2.3.3. Stanford
Синтаксический парсер Stanford – парсер, разработанный в Стендфордском университете. Данный парсер использует модель arc-standard system, где выбор действия осуществляется с помощью нейронной сети. Особенностью данного парсера является то, что он изначально был создан и обучен для применения на англоязычных текстах, при этом грамматика английского языка предполагает только 15 типов связей. При адаптации парсера для русского языка типы связей были сохранены. Однако русский язык содержит порядка 30 типов связей, что порождает значительные трудности в использовании данного парсера на русскоязычных текстах.
В процессе тестирования Stanford выдаёт минимальное количество разнородных, но зачастую несущественных ошибок, верно выявляя структуры сложносочинённых и сложноподчинённых предложений.

Здесь сочинительной связью «сonj» система объединила категории «пункте» и «Пленума», хотя из предыдущего разбора нам уже известно, что эта связь закреплена за словами «Пленума» и «Пленума».
Стоит также обратить внимание на следующую особенность: при том что словосочетание «Пленума ВС РФ» с его аббревиатурами разобрано верно (последовательная зависимость «nmod»: от «Пленума» к «ВС», от «ВС» к «РФ»), аналогичное словосочетание «Пленума ВАС РФ» уже требует корректив (вместо последовательности от «Пленума» как к «ВАС», так и к «РФ», необходима последовательная связь, аналогичная предыдущему словосочетанию), что говорит о нестабильном результате вывода. При этом относительно качественно разобраны структурные части предложения (причастные обороты, подчинительная часть).
В итоге к преимущества Stanford мы можем отнести устойчивую работу при анализе структуры предложения (что является существенным аргументом в пользу парсера) и полный разбор предложения без пропусков. К недостаткам — скорость обработки, некоторая хаотичность выделения связей между токенами (от глагола к прилагательному, а уже после через него к существительному).
3.2.3.4. UDPipe 2.4
Модель Universal Dependencies предобучена на нескольких русских размеченных корпусах, среди которых к сравнительному анализу были взяты следующие: GSD, taiga и SynTagRus. Безусловно, самой качественной среди них оказалась модель на SynTagRus – крупнейшем русском размеченном корпусе на сегодня.
UDP GSD
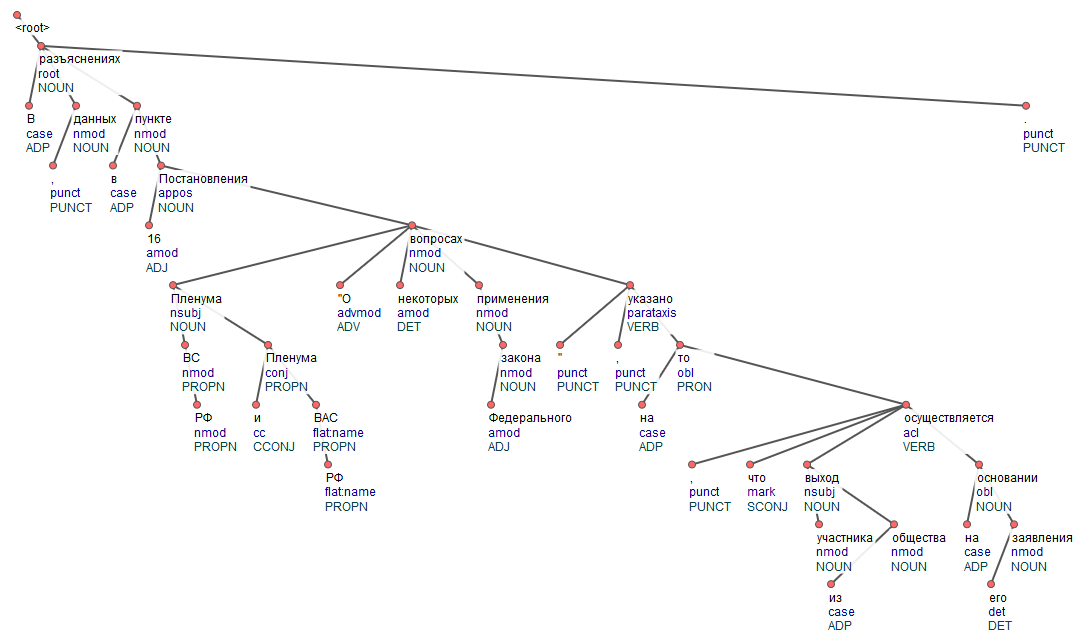
UDPipe, обученный на GSD, выдаёт частые ошибки внутри структуры предложений. В данном дереве имеющие прямую синтаксическую связь слова «разъяснениях» и «указано», разделены друг от друга 4 уровнями связей. Кроме того за root принимаются не только глаголы, но и существительные (не всегда подлежащие). На примере видно ошибочное определение «root» (разъяснениях), что значительно исказит дальнейший семантический анализ.
Также часто и бессистемно дроблению подвергаются длинные предложения. Насыщенность однородными членами также способна сломать структуру дерева. Зачастую, эти особенности обнаруживается на предложениях средней и высокой степени сложности.
UDP taiga
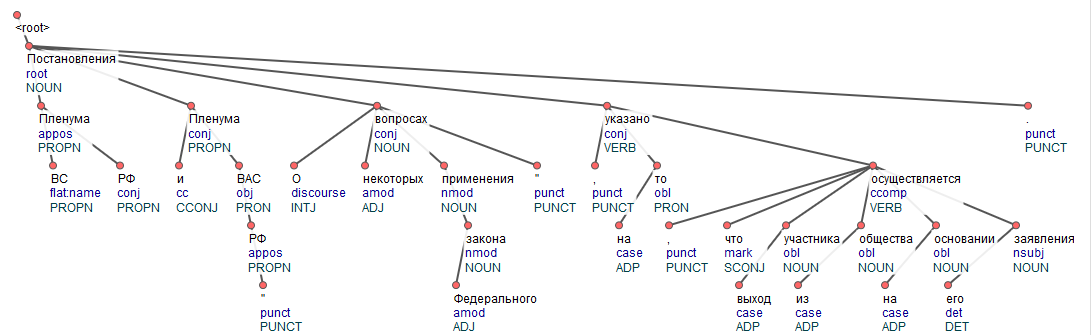
На аналогичном примере UDP 2.4 taiga продемонстрировала огромное количество искажений, но главной принципиальной ошибкой стало деление одного предложения на два дерева.
UDPipe, обученный на Taiga даёт аналогичные предыдущему корпусу ошибки, однако дробление предложения на несколько деревьев возникает зачастую уже на предложениях средней сложности.
UDP SynTagRus
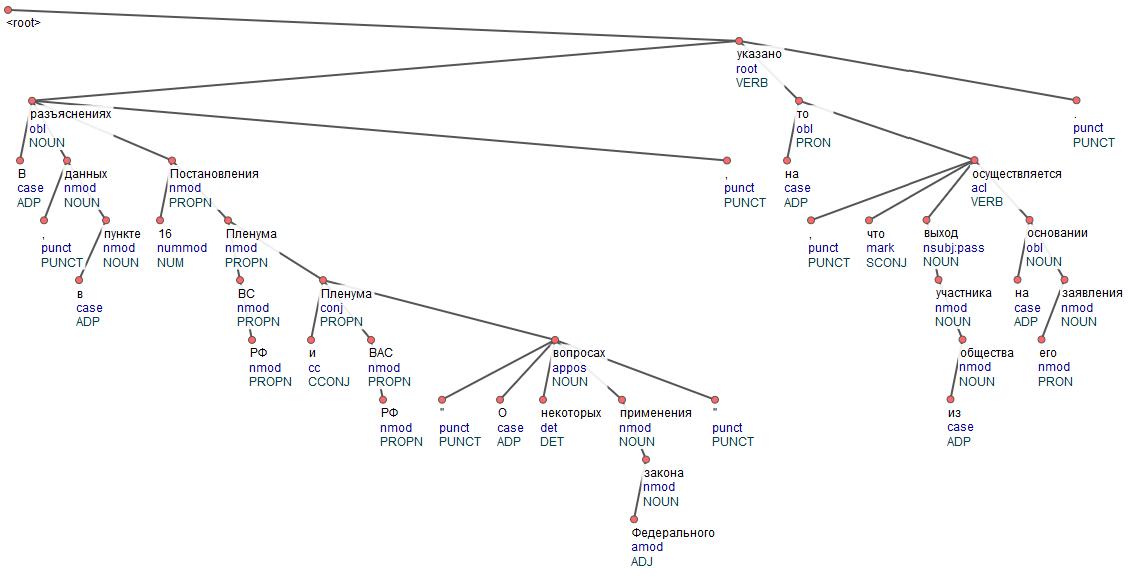
Иначе обстоят дела с UDP 2.4 SynTagRus. Он вывел качественно проанализированное дерево, недочётами которого стала последовательность связей (в словосочетании «выход участника из общества» «выход» должен быть напрямую связан с «обществом», а не через связь с «участником») и обработка числовых показателей (очевидно, «16»-ым является «пункт», а отнюдь не «Постановление»).
UDPipe на SynTagRus имеет более стойкие, отслеживаемые ошибки в предложениях высокой степени сложности. Однако структура остаётся сохранна, за исключением случаев особо нагромождённых предложений, которые парсер имеет свойство дробить.
В целом к явным плюсам UDPipe можно отнести скорость и обновляемость.
3.2.3.5. DeepPavlov
Последней была протестирована модель DeepPavlov, предобученая на корпусе SynTagRus с помощью BERT.

Модель показала очень достойные результаты, в целом приближенные к UDPipe 2.4 на SynTagRus. Наблюдаются проблемы на сложных многоуровневых предложениях, ошибки в месте связи или в её типе. На данном примере видим, пожалуй, единственный неочевидный нюанс с «Постановлением… «О вопросах…», где «Постановление» и «вопросах» должны иметь не опосредованную, а прямую связь (в контексте предложения наименование «О вопросах…» присвоено не Пленуму, а Постановлению).
3.2.3.6. Итоговые результаты тестирования синтаксических парсеров
Результаты тестирования существующих синтаксических парсеров можно представить в следующей таблице (инструменты ранжированы в зависимости от результатов — от наиболее успешного к наименее).
| № | Наименование | Преимущества | Недостатки |
|---|---|---|---|
| 1 | DeepPavlov | скорость, обновляемость и сохранение структуры предложения | нарушение последовательности связей в сложных предложениях |
| 2 | UDPipe 2.4 SynTagRus | скорость, обновляемость и сохранение структуры предложения | нарушение последовательности связей в сложных предложениях и числовых значениях |
| 3 | Stanford | устойчивая работа при анализе структуры предложения и полный разбор предложения без пропусков | низкая скорость обработки и хаотичность выделения связей между токенами |
| 4 | ЭТАП | присутствие дополнительных лексических функций/связей, позволяющих более глубоко работать с семантикой на следующих этапах | нарушение семантической логики связей, дробление числовых показателей и нахождение несуществующих связей |
| 5 | UDPipe 2.4 GSD | — | дробление предложений на два и более деревьев, ошибки в последовательности и типах связей |
| 6 | UDPipe 2.4 Taiga | — | дробление предложений на два и более деревьев |
| 7 | АОТ | — | неполнота связей (некоторые токены остаются «в воздухе», что недопустимо при создании графа и дальнейшем семантическом анализе) |
Исследованные инструменты показали различные результаты. Некоторые парсеры, например DeepPavlov, UDPipe 2.4 SinTagRus и Stanford, продемонстрировали относительно хороший уровень разбора простых предложений и предложений средней степени сложности, однако общим для них является неэффективность на юридических текстах. Для достижения приемлемого уровня разбора текстов правовых документов данные модели подлежат значительной доработке.
4. Заключение
4.1. Выводы по итогам тестирования
Результаты исследования существующих решений в области процессинга русскоязычного текста привели нас к выводу, что представленные на рынке инструменты имеют универсальный характер и неприменимы в существующем виде для достижения практических результатов в анализе слабоструктурированных и неструктурированных правовых документов. Причин тому несколько.
Основная проблема, присущая всем представленным решениям, заключается в том, что продукт создан не экспертами предметной области, в которой он применяется. Идея создания инструментов автоматизации юридической работы без участия юристов высокой квалификации изначально обречена на неудачу, поскольку без понимая терминологии, ее значений и классификаций, а также самых глубинных взаимосвязей невозможно воссоздать «юридическую картину мира». Во многом данная ситуация связана с тем, что на рынке доминируют подход, при котором идеологами проектов по созданию решений автоматизации выступают IT-разработчики и специалисты в области data science, которые не знакомы на должном уровне с особенностями юридического мышления и не погружены в реальную практику, в которой может применяться то или иное решение.
Кроме того, при создании программных продуктов многими разработчиками преследуется логичная цель — максимально широкая интеграция ПО в различные сферы. Наиболее простой подход для этого — создание универсальной платформы, внедрение которой в новую предметную область потребует незначительных доработок. Данный подход имеет свои преимущества и недостатки, но в случае создания инструментов автоматизации работы юриста он неприменим. Для использования таких продуктов конечные пользователи (практикующие юристы) вынуждены подстраиваться и адаптироваться под их условия и особенности, а в данной сфере должно быть наоборот — продукт изначально должен создаваться исходя из потребностей и задач пользователей. Только такой подход позволит добиться качественных результатов.
Третьим фактором, который до настоящего времени не позволил реализовать в полном объеме процессинг русскоязычных текстов на достаточном уровне, является недостаточность финансирования научных разработок и отсутствие государственных и частных инвестиций в данную область знаний. Существующие научные группы и институты благодаря собственной воле и энтузиазму достигли хороших практических результатов в создании инструментов обработки текста, однако ограниченность бюджета не позволяет им продвинуться дальше. Их зарубежные коллеги достигли гораздо больших результатов благодаря активному участию государства, финансирующего подобные проекты. По нашему мнению, государственная поддержка исследователей и проектов в области NLP и искусственного интеллекта позволит совершить настоящий прорыв в краткосрочной перспективе.
4.2. Дальнейшее развитие
Как показывает практика, создать высокоэффективное программное решение, которое может быть интегрировано в конкретную предметную область, невозможно без участия экспертов из данной области, профессиональный опыт и логика которых ложатся в основу машинных алгоритмов. Именно поэтому мы считаем, что создание «цифрового юриста» (юридического ИИ) и содержательная автоматизация юридической функции:
- возможны только в результате глубинного погружения в предметную область;
- находятся на пересечении 3 различных областей знаний: юриспруденция, лингвистика и IT.
В результате тесного взаимодействия специалистов из этих областей будут созданы новые уникальные для рынка компетенции. Данные компетенции находятся на стыке нескольких областей — юриспруденции, лингвистики, программирования и инженерии знаний, что приведет к формированию принципиально новых профессий, отсутствие которых сегодня является одним из наиболее существенных факторов, сдерживающих развитие рынка технологий искусственного интеллекта в России.
Решение задачи процессинга неструктурированного русскоязычного текста в области юриспруденции требует иного подхода к использованию инструментов NLP: они должны учитывать на фундаментальном уровне юридические концепты и базироваться на графах знаний, которые изначально созданы для решения узкопрофильных юридических задач. Это позволит воссоздать юридическую «картину мира» в цифровом формате и трансформировать юридическую логику в машинные алгоритмы. Безусловно, большое значение в данном вопросе имеет достаточный уровень финансирования и поддержки подобных проектов, которое возможно только при активном участии государства.


























